GPT-SoVITS
大约 3 分钟computer
概述
初次接触这个项目通过 B站链接,声音克隆的开源项目,点击打开 官网
安装
- 50系显卡整合包:https://pan.quark.cn/s/af8e12a1a446 下载后拷贝到自己公司的250服务器上
\\192.168.0.250\alist\安装程序\cc\GPT-SoVITS\GPT-SoVITS-v2pro-20250604-nvidia50.7z - 50以下显卡整合包:https://pan.quark.cn/s/68d197c32245 下载后拷贝到自己公司的250服务器上
\\192.168.0.250\alist\安装程序\cc\GPT-SoVITS\GPT-SoVITS-v2pro-20250604.7z - mac版一键整合包:https://pan.quark.cn/s/733245e040f2
- 官方推荐的模型分享社区:https://www.ai-hobbyist.com/
最简单使用
解压 GPT-SoVITS-v2pro-20250604.7z (非50系显卡)后双击运行 go-webui.bat 后出现 cmd 并自动打开网页,注意很窗口不可关闭。该页面中可以设置自己的模型,如果没有,使用默认的话就直接点击跳转到推理页面
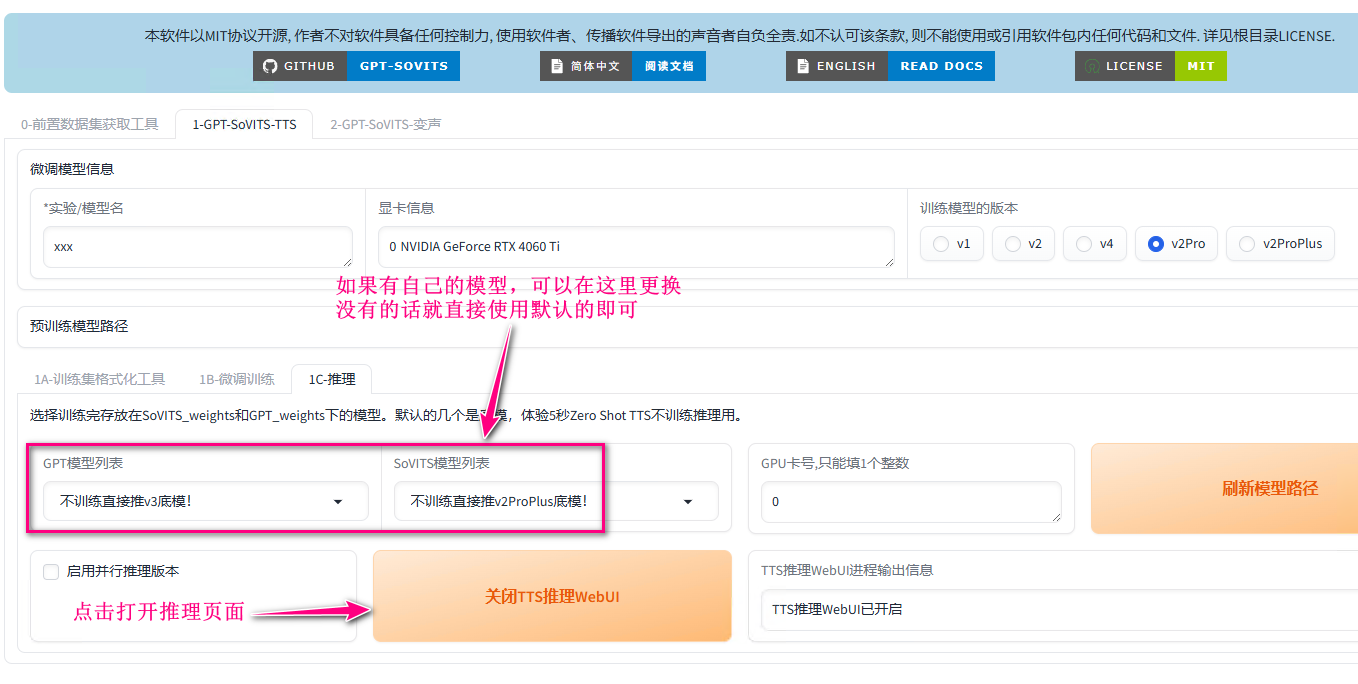
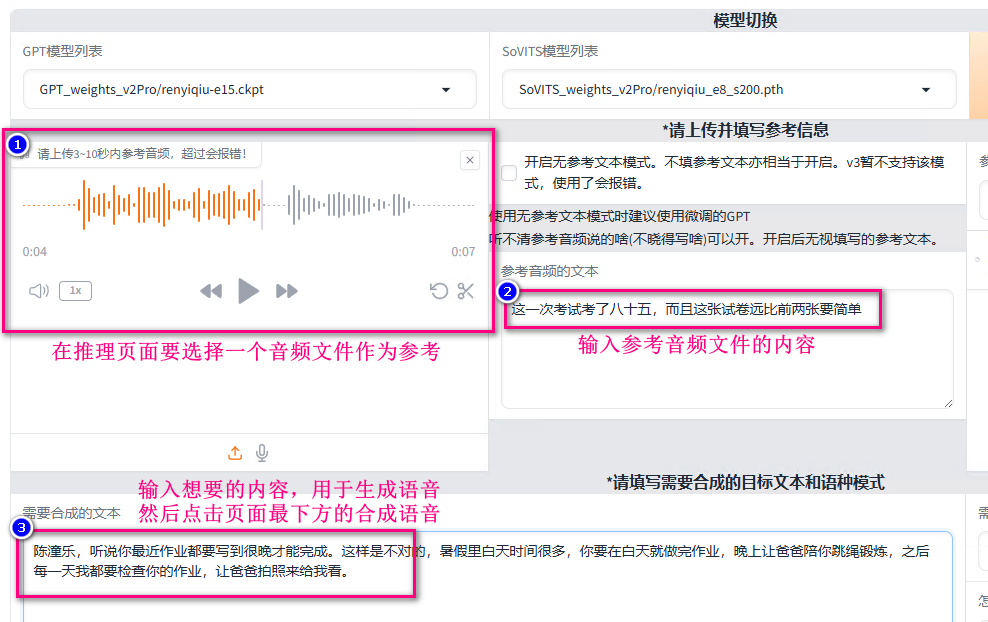
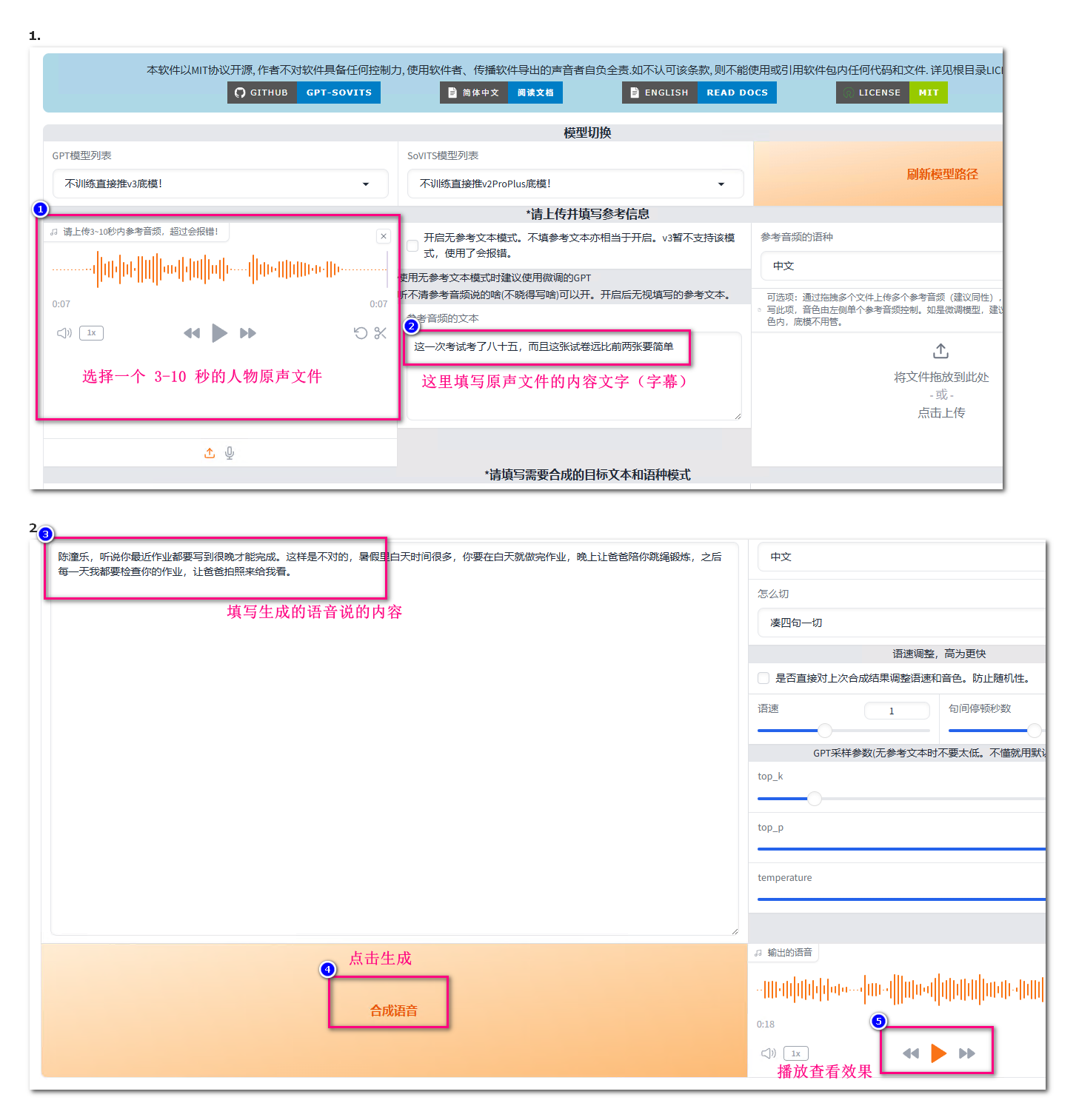
进入推理页面按照下图的标号顺序操作
训练模型
- 大文件拆分
如果手上的音频文件是带有背景音的需要先分离人声,音频文件过大(时长超过10秒)需要先拆分,这里从拆分开始讲起,按照下图拆分大文件
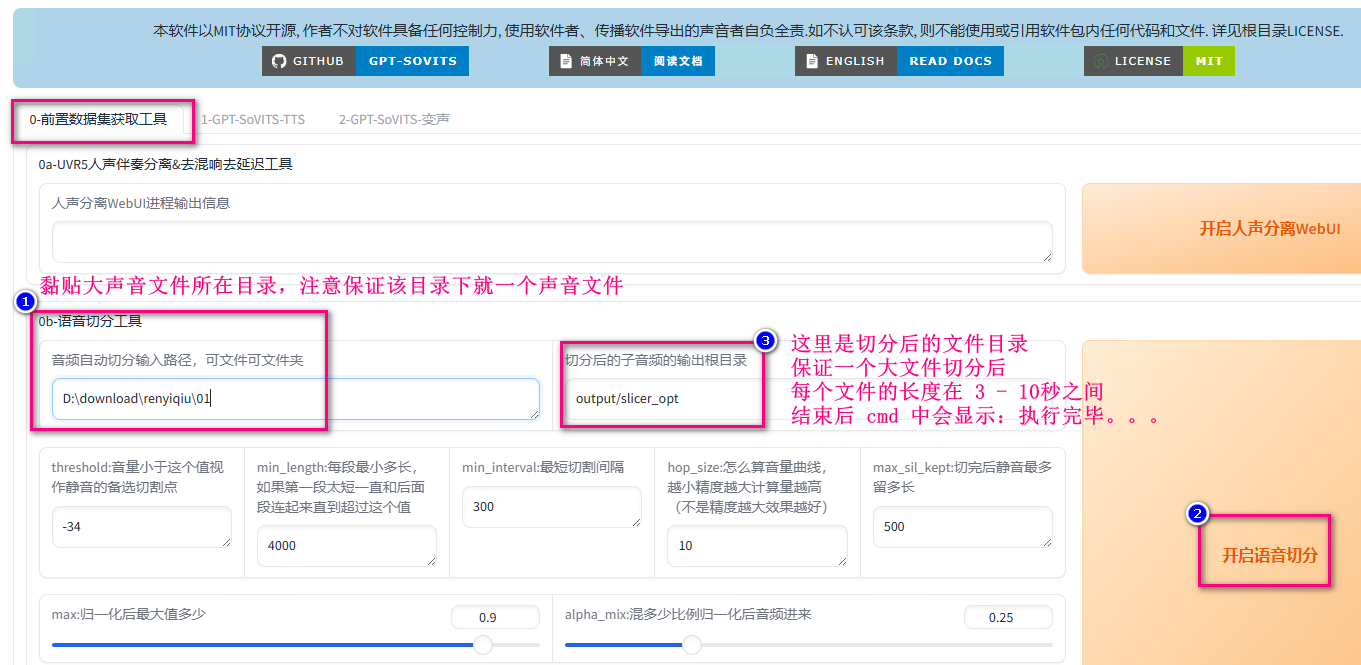
拆分后的文件路径是 D:\download\GPT-SoVITS-v2pro-20250604\output\slicer_opt,尽量多一些语料文件,本次试验使用了拆分后的10个小文件
自动字幕
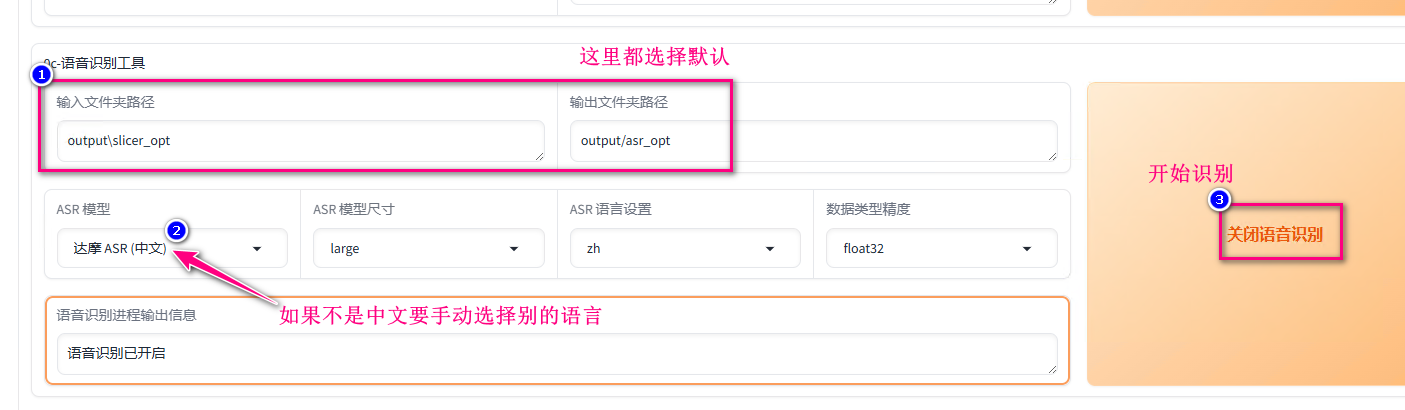
将上面拆分后的音频文件识别出文字,后面的训练要用到。下图默认的输入文件夹就是上一步的拆分文件后的目录,输出文件夹是识别后文字内容文件所在的目录
手动对音频文件标注,上一步中自动生成的文字内容有可能有出入,在这一步中人工进行校准。在软件的 web 页面中叫做 开启音频标准 WebUI,会自动打开一个新页面,逐个文件播放并校准文字。
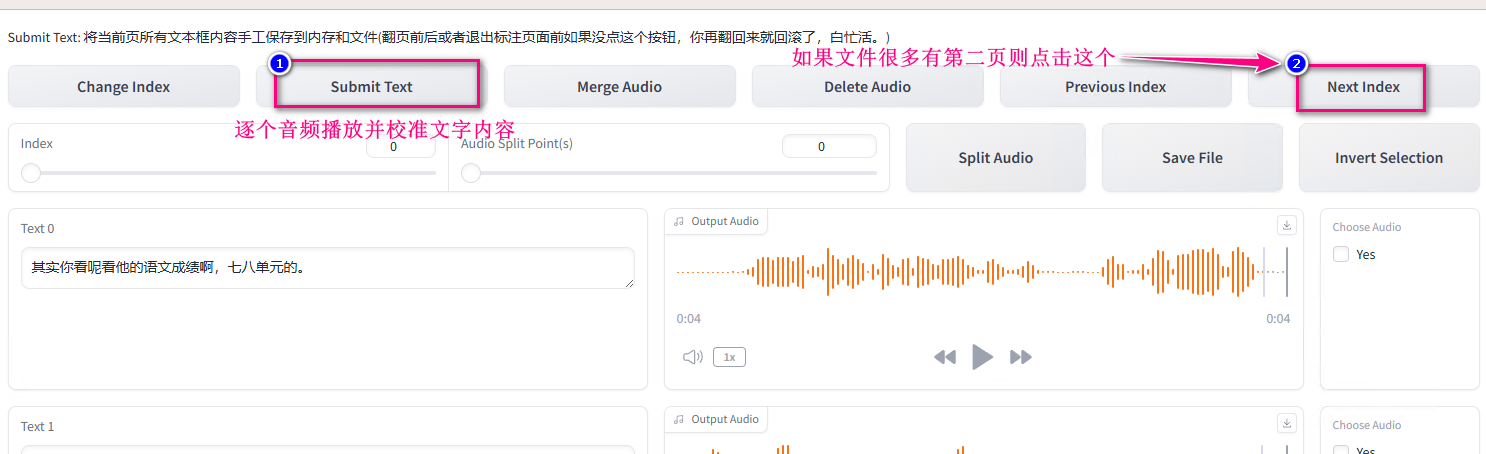
最后记得关闭音频标准页面,并关闭音频识别按钮。
准备好素材后开始训练的第一步
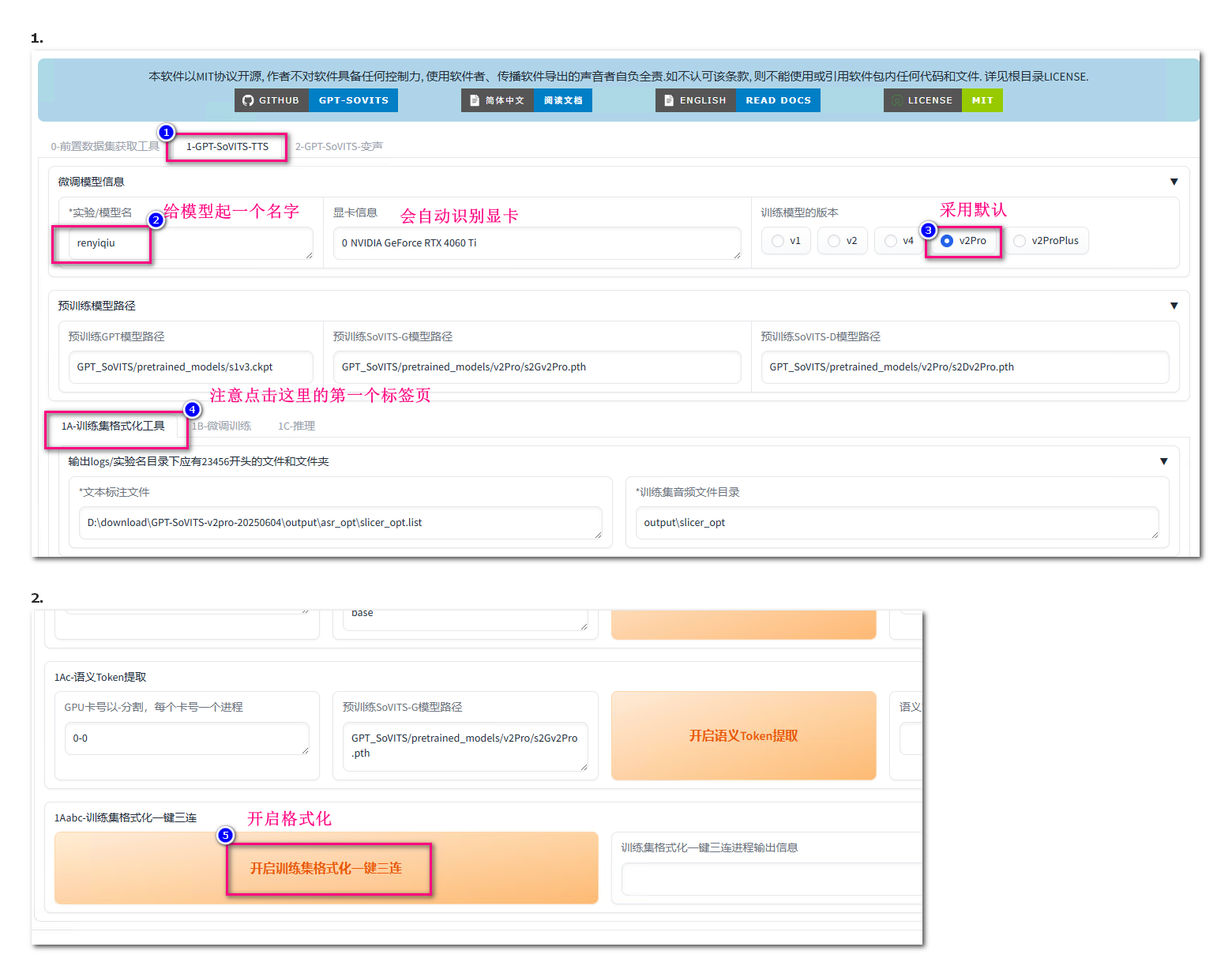
完成的话右边的 “训练集格式化一键三连进程输出信息” 中会显示已完成,进入下一步
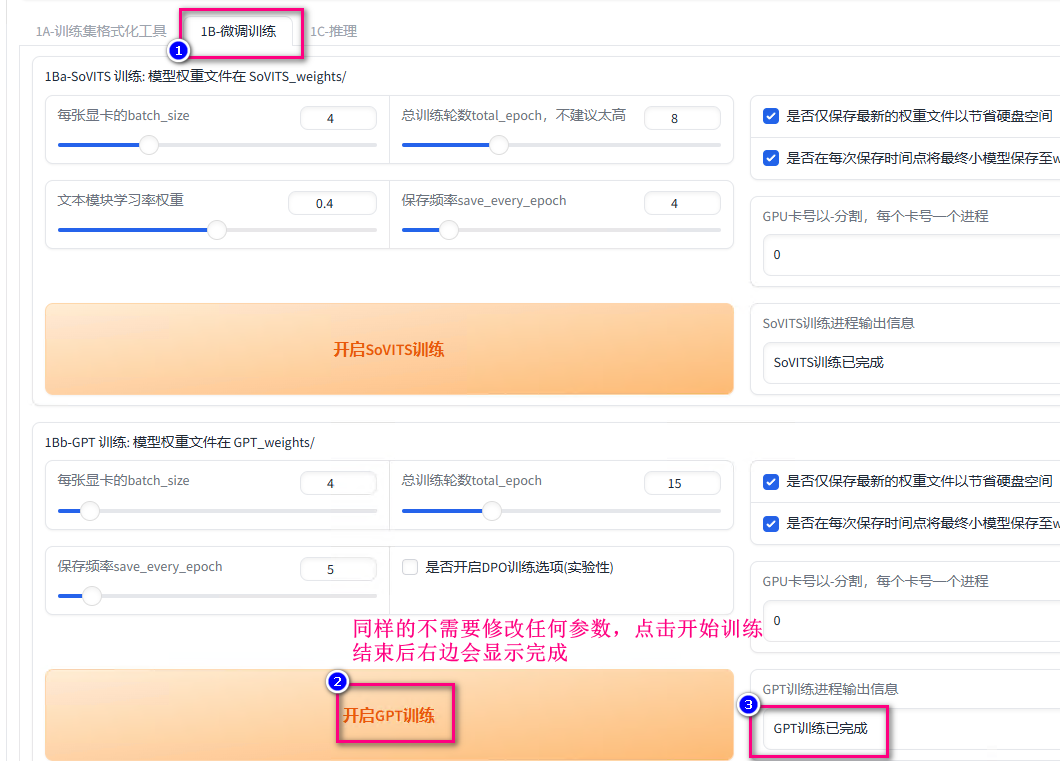
- 训练SoVITS
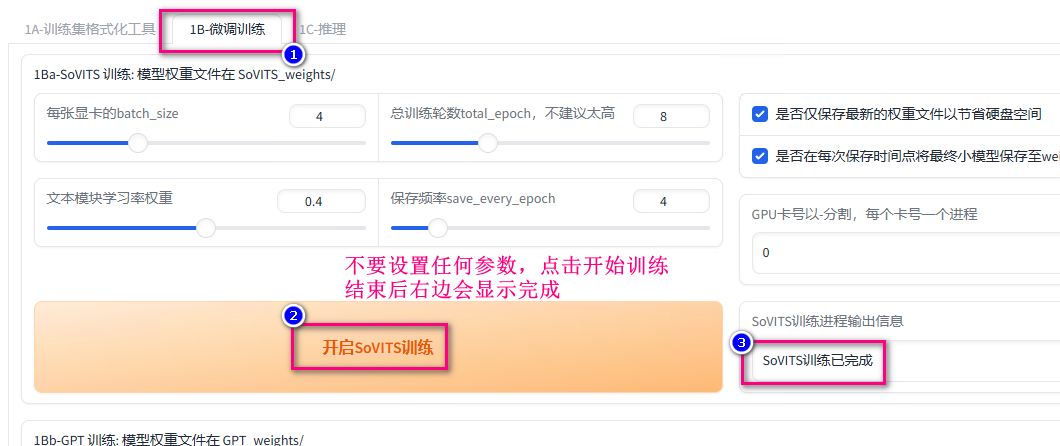
成功后在路径 D:\download\GPT-SoVITS-v2pro-20250604\SoVITS_weights_v2Pro 下会生成模型文件 renyiqiu_e4_s100.pth 和 renyiqiu_e8_s200.pth
- 训练GPT
使用自定义模型推理

在推理页面要设置3处后进行合成语音,这里上传的音频文件用于模拟:情感、语速、语调