13. snippet
大约 24 分钟编程语言数据库mysql
DDL
# 创建数据库
CREATE DATABASE IF NOT EXISTS [dbName] DEFAULT CHARSET utf8mb4
COLLATE utf8mb4_general_ci;
# 创建存储过程
DROP PROCEDURE IF EXISTS `[procName]`;
delimiter $
# 下面的 `root`@`%`表示允许任意机器上通过用户root使用本存储过程
CREATE DEFINER=`root`@`%` PROCEDURE `[procName]`(IN inParentid INT)
BEGIN
END;$
# 创建表
CREATE TABLE `area` (
`sId` VARCHAR(50) NOT NULL COMMENT '地区编号' COLLATE 'utf8_general_ci',
`name` VARCHAR(50) NULL DEFAULT NULL COMMENT '地区名称' COLLATE 'utf8_general_ci',
`parent` VARCHAR(50) NULL DEFAULT NULL COMMENT '上级编号' COLLATE 'utf8_general_ci',
`status` INT(11) NULL DEFAULT '0' COMMENT '0正常,1停用,2删除',
`serialNO` FLOAT NULL DEFAULT NULL COMMENT '排序序号',
`remark` VARCHAR(50) NULL DEFAULT NULL COLLATE 'utf8_general_ci',
`createDate` DATETIME NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建日期,DB自动填充',
PRIMARY KEY (`sId`) USING BTREE
)
COMMENT='地区'
COLLATE='utf8_general_ci'
ENGINE=InnoDB
;
Exists
SELECT a.*
from product_file_bom a
where a.parent_id = productId
and exists(select * from product_file b where b.pf_coded = a.pf_coded)
;
统计相关
数据库
# 查看指定数据库下所有表的行数、数据容量MB、索引容量
select
table_schema as 'db',
table_name as 'table',
table_rows as 'rows',
truncate(data_length/1024/1024, 2) as '数据容量(MB)',
truncate(index_length/1024/1024, 2) as '索引容量(MB)'
from information_schema.tables
where table_schema='weixin_cloud'
order by data_length desc, index_length desc;
逐日累计
字段 totalMoney 是每日累计下来的销售金额,如果当日有收款则要减少对应的金额,totalSales 是每日累计的销售额,和收款没有关系,有收款时不要计算即可
# 创建表
-- auto-generated definition
CREATE TABLE current_account (
iid INT AUTO_INCREMENT COMMENT '自增主键' PRIMARY KEY,
bill_date DATETIME DEFAULT CURRENT_TIMESTAMP NULL COMMENT '业务发生日期',
remark VARCHAR(100) DEFAULT '' NULL COMMENT '备注',
type VARCHAR(100) DEFAULT '' NULL COMMENT '业务类型:欠款、收款',
money DECIMAL(20,4) DEFAULT 0.0000 NULL COMMENT '金额',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP NULL COMMENT '创建时间,DB自动填充'
) COMMENT '往来账款';
# 插入数据
INSERT INTO gsms_log.current_account (iid, bill_date, remark, type, money, create_time) VALUES (1, '2021-08-01 11:40:47', '上期结余', '1', 1120.0000, '2021-08-12 19:42:29');
INSERT INTO gsms_log.current_account (iid, bill_date, remark, type, money, create_time) VALUES (2, '2021-08-02 11:40:55', '法兰绒,180G', '1', 2000.0000, '2021-08-12 19:42:29');
INSERT INTO gsms_log.current_account (iid, bill_date, remark, type, money, create_time) VALUES (3, '2021-08-03 11:41:18', 'PV绒,200G', '1', 6600.0000, '2021-08-12 19:42:29');
INSERT INTO gsms_log.current_account (iid, bill_date, remark, type, money, create_time) VALUES (4, '2021-08-05 11:41:40', '收现金', '-1', 8800.0000, '2021-08-12 19:42:29');
INSERT INTO gsms_log.current_account (iid, bill_date, remark, type, money, create_time) VALUES (5, '2021-08-07 11:42:07', '兔毛,18毛', '1', 3000.0000, '2021-08-12 19:42:29');
# 实现逻辑
select a.*,@totalMoney := @totalMoney + a.money * a.type AS totalMoney,
@totalSales := @totalSales + a.money * CASE WHEN a.type = -1 THEN 0 ELSE a.type END AS totalSales
from current_account AS a,(SELECT @totalMoney :=0,@totalSales := 0) AS b
where 1=1;
快速开发框架
批量读取表字段并设置到字段样式表中
SET @dbName = 'atools';
SET @tableName = 'life_schedule';
SET @is_column = 0;
DELETE FROM table_style WHERE table_name = @tableName;
INSERT INTO table_style
(table_name,field_name,`text`,bool_column)
SELECT TABLE_NAME AS table_name,COLUMN_NAME AS field_name,
SUBSTRING_INDEX(t1.COLUMN_COMMENT,',',1) AS TEXT,b'0'
FROM information_schema.columns t1
WHERE table_schema=@dbName AND table_name=@tableName;
构建通用权限数据
DELIMITER $$
SET @controllerName = 'filterDatasource';# 填写JAVA中控制器别名
SET @insertUrl = concat('/',@controllerName,'/','insert');
SET @deleteUrl = concat('/',@controllerName,'/','deleteByPrimaryKey');
SET @selectByPrimaryKeyUrl = concat('/',@controllerName,'/','selectByPrimaryKey');
SET @selectAll = concat('/',@controllerName,'/','selectAll');
SET @update = concat('/',@controllerName,'/','update');
INSERT INTO sys_permission
(permissionid, type, url, http_method)
VALUES
(@insertUrl,'新增',@insertUrl,'post'),
(concat(@deleteUrl,'/{iid}'),'删除',@deleteUrl,'delete'),
(concat(@selectByPrimaryKeyUrl,'/{iid}'),'查询',@selectByPrimaryKeyUrl,'get'),
(@selectAll,'查询',@selectAll,'get'),
(@update,'修改',@update,'put');
DELIMITER ;
字符串相关
取汉字拼音
下面功能函数的使用案例是:select to_pinyin('123 中文 ……中a ^华b人 c $民 d共[和]国 Good!',3);
drop function if exists to_pinyin;
delimiter //
create function to_pinyin(name varchar(255) charset gbk, flag int) returns varchar(255) charset gbk
begin
# flag:
# 1 - 所有拼音采用小写
# 2 - 所有拼音采用大写
# 3 - 全拼的首字母大写,其余小写
declare mycode int;
declare tmp_lcode varchar(2) charset gbk;
declare lcode int;
declare tmp_rcode varchar(2) charset gbk;
declare rcode int;
declare l_pin_yin_ varchar(6);
declare mypy varchar(255) charset gbk default '';
declare lp int;
set mycode = 0;
set lp = 1;
set name = hex(name);
while lp < length(name) do
set tmp_lcode = substring(name, lp, 2);
set lcode = cast(ascii(unhex(tmp_lcode)) as unsigned);
set tmp_rcode = substring(name, lp + 2, 2);
set rcode = cast(ascii(unhex(tmp_rcode)) as unsigned);
if lcode > 128 then
set mycode =abs(65536 - lcode * 256 - rcode);
-- 取对应的拼音
set l_pin_yin_ = elt(interval(0-mycode,
-20319,-20317,-20304,-20295,-20292,-20283,-20265,-20257,-20242,-20230,-20051,-20036,
-20032,-20026,-20002,-19990,-19986,-19982,-19976,-19805,-19784,-19775,-19774,-19763,
-19756,-19751,-19746,-19741,-19739,-19728,-19725,-19715,-19540,-19531,-19525,-19515,
-19500,-19484,-19479,-19467,-19289,-19288,-19281,-19275,-19270,-19263,-19261,-19249,
-19243,-19242,-19238,-19235,-19227,-19224,-19218,-19212,-19038,-19023,-19018,-19006,
-19003,-18996,-18977,-18961,-18952,-18783,-18774,-18773,-18763,-18756,-18741,-18735,
-18731,-18722,-18710,-18697,-18696,-18526,-18518,-18501,-18490,-18478,-18463,-18448,
-18447,-18446,-18239,-18237,-18231,-18220,-18211,-18201,-18184,-18183,-18181,-18012,
-17997,-17988,-17970,-17964,-17961,-17950,-17947,-17931,-17928,-17922,-17759,-17752,
-17733,-17730,-17721,-17703,-17701,-17697,-17692,-17683,-17676,-17496,-17487,-17482,
-17468,-17454,-17433,-17427,-17417,-17202,-17185,-16983,-16970,-16942,-16915,-16733,
-16708,-16706,-16689,-16664,-16657,-16647,-16474,-16470,-16465,-16459,-16452,-16448,
-16433,-16429,-16427,-16423,-16419,-16412,-16407,-16403,-16401,-16393,-16220,-16216,
-16212,-16205,-16202,-16187,-16180,-16171,-16169,-16158,-16155,-15959,-15958,-15944,
-15933,-15920,-15915,-15903,-15889,-15878,-15707,-15701,-15681,-15667,-15661,-15659,
-15652,-15640,-15631,-15625,-15454,-15448,-15436,-15435,-15419,-15416,-15408,-15394,
-15385,-15377,-15375,-15369,-15363,-15362,-15183,-15180,-15165,-15158,-15153,-15150,
-15149,-15144,-15143,-15141,-15140,-15139,-15128,-15121,-15119,-15117,-15110,-15109,
-14941,-14937,-14933,-14930,-14929,-14928,-14926,-14922,-14921,-14914,-14908,-14902,
-14894,-14889,-14882,-14873,-14871,-14857,-14678,-14674,-14670,-14668,-14663,-14654,
-14645,-14630,-14594,-14429,-14407,-14399,-14384,-14379,-14368,-14355,-14353,-14345,
-14170,-14159,-14151,-14149,-14145,-14140,-14137,-14135,-14125,-14123,-14122,-14112,
-14109,-14099,-14097,-14094,-14092,-14090,-14087,-14083,-13917,-13914,-13910,-13907,
-13906,-13905,-13896,-13894,-13878,-13870,-13859,-13847,-13831,-13658,-13611,-13601,
-13406,-13404,-13400,-13398,-13395,-13391,-13387,-13383,-13367,-13359,-13356,-13343,
-13340,-13329,-13326,-13318,-13147,-13138,-13120,-13107,-13096,-13095,-13091,-13076,
-13068,-13063,-13060,-12888,-12875,-12871,-12860,-12858,-12852,-12849,-12838,-12831,
-12829,-12812,-12802,-12607,-12597,-12594,-12585,-12556,-12359,-12346,-12320,-12300,
-12120,-12099,-12089,-12074,-12067,-12058,-12039,-11867,-11861,-11847,-11831,-11798,
-11781,-11604,-11589,-11536,-11358,-11340,-11339,-11324,-11303,-11097,-11077,-11067,
-11055,-11052,-11045,-11041,-11038,-11024,-11020,-11019,-11018,-11014,-10838,-10832,
-10815,-10800,-10790,-10780,-10764,-10587,-10544,-10533,-10519,-10331,-10329,-10328,
-10322,-10315,-10309,-10307,-10296,-10281,-10274,-10270,-10262,-10260,-10256,-10254),
'a','ai','an','ang','ao','ba','bai','ban','bang','bao','bei','ben',
'beng','bi','bian','biao','bie','bin','bing','bo','bu','ca','cai','can',
'cang','cao','ce','ceng','cha','chai','chan','chang','chao','che','chen','cheng',
'chi','chong','chou','chu','chuai','chuan','chuang','chui','chun','chuo','ci','cong',
'cou','cu','cuan','cui','cun','cuo','da','dai','dan','dang','dao','de',
'deng','di','dian','diao','die','ding','diu','dong','dou','du','duan','dui',
'dun','duo','e','en','er','fa','fan','fang','fei','fen','feng','fo',
'fou','fu','ga','gai','gan','gang','gao','ge','gei','gen','geng','gong',
'gou','gu','gua','guai','guan','guang','gui','gun','guo','ha','hai','han',
'hang','hao','he','hei','hen','heng','hong','hou','hu','hua','huai','huan',
'huang','hui','hun','huo','ji','jia','jian','jiang','jiao','jie','jin','jing',
'jiong','jiu','ju','juan','jue','jun','ka','kai','kan','kang','kao','ke',
'ken','keng','kong','kou','ku','kua','kuai','kuan','kuang','kui','kun','kuo',
'la','lai','lan','lang','lao','le','lei','leng','li','lia','lian','liang',
'liao','lie','lin','ling','liu','long','lou','lu','lv','luan','lue','lun',
'luo','ma','mai','man','mang','mao','me','mei','men','meng','mi','mian',
'miao','mie','min','ming','miu','mo','mou','mu','na','nai','nan','nang',
'nao','ne','nei','nen','neng','ni','nian','niang','niao','nie','nin','ning',
'niu','nong','nu','nv','nuan','nue','nuo','o','ou','pa','pai','pan',
'pang','pao','pei','pen','peng','pi','pian','piao','pie','pin','ping','po',
'pu','qi','qia','qian','qiang','qiao','qie','qin','qing','qiong','qiu','qu',
'quan','que','qun','ran','rang','rao','re','ren','reng','ri','rong','rou',
'ru','ruan','rui','run','ruo','sa','sai','san','sang','sao','se','sen',
'seng','sha','shai','shan','shang','shao','she','shen','sheng','shi','shou','shu',
'shua','shuai','shuan','shuang','shui','shun','shuo','si','song','sou','su','suan',
'sui','sun','suo','ta','tai','tan','tang','tao','te','teng','ti','tian',
'tiao','tie','ting','tong','tou','tu','tuan','tui','tun','tuo','wa','wai',
'wan','wang','wei','wen','weng','wo','wu','xi','xia','xian','xiang','xiao',
'xie','xin','xing','xiong','xiu','xu','xuan','xue','xun','ya','yan','yang',
'yao','ye','yi','yin','ying','yo','yong','you','yu','yuan','yue','yun',
'za','zai','zan','zang','zao','ze','zei','zen','zeng','zha','zhai','zhan',
'zhang','zhao','zhe','zhen','zheng','zhi','zhong','zhou','zhu','zhua','zhuai','zhuan',
'zhuang','zhui','zhun','zhuo','zi','zong','zou','zu','zuan','zui','zun','zuo');
if l_pin_yin_ is null then -- 非汉字取原字符
set mypy = concat(mypy,convert(unhex(substring(name, lp, 4)) using gbk));
else -- 汉字取拼音
set l_pin_yin_ = case flag
when 1 then lower(l_pin_yin_)
when 2 then upper(l_pin_yin_)
when 3 then concat(upper(substr(l_pin_yin_,1,1)),lower(substr(l_pin_yin_,2)))
else lower(l_pin_yin_)
end;
set mypy = concat(mypy,l_pin_yin_);
end if;
set lp = lp + 4;
else -- ASCII字符
set mypy = concat(mypy,char(cast(ascii(unhex(substring(name, lp, 2))) as unsigned)));
set lp = lp + 2;
end if;
end while;
return mypy;
end;
//
delimiter ;
按位序截取
看下面代码,将字段 line 中的内容按照 /F 进行分割,取分割后前面部分的内容则在该函数的第三个参数上使用1,取分割后后面部分的内容则位序是-1。例如:将字符串 A/F压线:182369 使用该函数进行分割后,位序1得到的结果是 A,位序-1得到的结果是 压线:182369
select product_file.*,substring_index(line,'/F',1) AS wlpre,substring_index(line,'/F',-1) AS linesuf
取中间段 - 多次截取
两次使用 substring_index 截取 0299-01063-C405 的中间段
# 0299-01063-C405 截取中间段 01063
update product_file a
JOIN product_file_category b on a.category_id = b.id
set a.supplier_id = substring_index(substring_index(a.pf_coded,'-',2),'-',-1)
where b.use_type = 2 and substring(a.pf_coded,1,5)='0299-';
提取数字
DELIMITER $$
CREATE FUNCTION `usf_extractNumber`(in_string VARCHAR(50))
RETURNS INT
NO SQL
BEGIN
DECLARE ctrNumber VARCHAR(50);
DECLARE finNumber VARCHAR(50) DEFAULT '';
DECLARE sChar VARCHAR(1);
DECLARE inti INTEGER DEFAULT 1;
IF LENGTH(in_string) > 0 THEN
WHILE(inti <= LENGTH(in_string)) DO
SET sChar = SUBSTRING(in_string, inti, 1);
SET ctrNumber = FIND_IN_SET(sChar, '0,1,2,3,4,5,6,7,8,9');
IF ctrNumber > 0 THEN
SET finNumber = CONCAT(finNumber, sChar);
END IF;
SET inti = inti + 1;
END WHILE;
RETURN CAST(finNumber AS UNSIGNED);
ELSE
RETURN 0;
END IF;
END$$
DELIMITER ;
主键值字符串转换为名称字符串
最终效果:
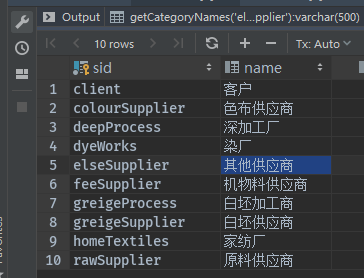
上面的分类表,将字符串client,deepProcess,dyeWorks 转换为对应名称的间隔字串,结果是 客户,深加工厂,染厂,下面是完整的SQL语句
DELIMITER $$;
CREATE FUNCTION getCategoryNames(categories VARCHAR(500))
RETURNS VARCHAR(500)
BEGIN
DECLARE rtn VARCHAR(500);
DECLARE ins VARCHAR(500);
IF right(categories,1) != ','
THEN SET ins = concat(categories,',');
END IF;
SELECT group_concat(b.name)
FROM
(
SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(ins,',',help_topic_id+1),',',-1) AS categorySid
FROM mysql.help_topic
WHERE help_topic_id < LENGTH(ins)-LENGTH(REPLACE(ins,',',''))+1
) a
LEFT OUTER JOIN contactcategory b
ON a.categorySid = b.sid
INTO rtn;
RETURN rtn;
END $$;
DELIMITER ;
- 下面是建表语句:
create table contactcategory (
sid varchar(30) charset utf8 not null,
name varchar(50) charset utf8 null,
pid int null comment '所属上级的ID',
serialno int null comment '排序序号',
status int null comment '状态,0表示作废',
createdate datetime default CURRENT_TIMESTAMP not null comment '创建时间',
UpdateTime datetime default CURRENT_TIMESTAMP null comment '最后一次修改时间',
visible int default 1 null comment '默认1表示可见,0表示不可见',
seq float null comment '排序序号',
constraint contactcategory_id_uindex unique (sid)
) comment '往来单位类型,一级节点的所属上级为-1'
collate = utf8_unicode_ci;
alter table contactcategory
add primary key (sid);
- 下面是插入数据语句:
INSERT INTO femis.contactcategory (sid, name, pid, serialno, status, createdate, UpdateTime, visible, seq) VALUES ('client', '客户', 1, null, null, '2019-06-03 15:45:45', '2019-06-03 15:55:02', 1, 20);
INSERT INTO femis.contactcategory (sid, name, pid, serialno, status, createdate, UpdateTime, visible, seq) VALUES ('colourSupplier', '色布供应商', 2, null, null, '2019-06-03 15:45:45', '2019-06-03 15:55:02', 1, 13);
INSERT INTO femis.contactcategory (sid, name, pid, serialno, status, createdate, UpdateTime, visible, seq) VALUES ('deepProcess', '深加工厂', 3, null, null, '2019-06-10 15:28:07', '2019-06-10 15:28:07', 1, 18);
INSERT INTO femis.contactcategory (sid, name, pid, serialno, status, createdate, UpdateTime, visible, seq) VALUES ('dyeWorks', '染厂', 3, null, null, '2019-06-03 15:45:45', '2019-06-03 15:55:02', 1, 17);
INSERT INTO femis.contactcategory (sid, name, pid, serialno, status, createdate, UpdateTime, visible, seq) VALUES ('elseSupplier', '其他供应商', 2, null, null, '2019-06-03 15:45:45', '2019-06-03 15:55:02', 1, 15);
INSERT INTO femis.contactcategory (sid, name, pid, serialno, status, createdate, UpdateTime, visible, seq) VALUES ('feeSupplier', '机物料供应商', 2, null, null, '2019-06-03 15:45:45', '2019-06-03 15:55:02', 1, 14);
INSERT INTO femis.contactcategory (sid, name, pid, serialno, status, createdate, UpdateTime, visible, seq) VALUES ('greigeProcess', '白坯加工商', 3, null, null, '2019-06-22 22:38:53', '2019-06-22 22:38:53', 1, 16);
INSERT INTO femis.contactcategory (sid, name, pid, serialno, status, createdate, UpdateTime, visible, seq) VALUES ('greigeSupplier', '白坯供应商', 2, null, null, '2019-06-03 15:45:45', '2019-06-03 15:55:02', 1, 12);
INSERT INTO femis.contactcategory (sid, name, pid, serialno, status, createdate, UpdateTime, visible, seq) VALUES ('homeTextiles', '家纺厂', 3, null, null, '2019-06-11 16:21:01', '2019-06-11 16:21:01', 1, 19);
INSERT INTO femis.contactcategory (sid, name, pid, serialno, status, createdate, UpdateTime, visible, seq) VALUES ('rawSupplier', '原料供应商', 2, null, null, '2019-06-03 15:45:45', '2019-06-03 15:55:02', 1, 11);
- 创建表插入数据后使用嘴上面的SQL语句测试
删除特殊符号和前后空格
update product_file set product_number = replace(replace(replace(product_number,char(9),''),char(10),''),char(13),'');
update product_file set product_number = rtrim(ltrim(product_number));
如果使用 trim 无法删除字符串前后的空格,则使用下面的函数,调用方法 SELECT clean_invisible_chars('巴旦木夹心巧克箱') AS cleaned;
create definer = root@`%` function clean_invisible_chars(str text) returns text deterministic
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE len INT;
DECLARE result TEXT DEFAULT '';
DECLARE c CHAR(1);
IF str IS NULL THEN
RETURN NULL;
END IF;
SET len = CHAR_LENGTH(str);
WHILE i <= len DO
SET c = SUBSTRING(str, i, 1);
-- 保留可见字符(ASCII 32~126 + 常见中文等),去掉控制字符和不可见空格
-- 这里简单处理:ASCII < 32 或 CHAR(160) 替换为空格,其余保留
IF ORD(c) < 32 OR ORD(c) = 160 THEN
SET result = CONCAT(result, ' '); -- 或直接 '' 来彻底删除
ELSE
SET result = CONCAT(result, c);
END IF;
SET i = i + 1;
END WHILE;
-- 最后再 TRIM 前后空格
RETURN TRIM(result);
END;
字符串拆分为多行表数据
SET @content = '7654,7698,7782,7788';
SELECT
SUBSTRING_INDEX(SUBSTRING_INDEX(@content,',',help_topic_id+1),',',-1) AS num
FROM
mysql.help_topic
WHERE
help_topic_id < LENGTH(@content)-LENGTH(REPLACE(@content,',',''))+1
字符串合计,使用间隔符号拼接
# 将表 ContactCategory 中字段 name 的值使用英文逗号拼接起来
Select group_concat(name) name
FROM contactcategory
表字段拼接为字符串
SELECT group_concat(fieldname) fieldname
FROM (
SELECT 1 AS id,column_name AS fieldname,column_comment AS comment
FROM information_schema.columns t1
WHERE table_schema='femis' AND table_name='orderdetail'
) t2;
表字段拼接为带有前后缀的字符串
# 2020年5月19日22:14:57,使用说明:
# 本工具一般用于生成单据序时表的存储过程的 select 之后的字段
# 参数 @prefix 为存储过程中物理表的别名,参数 @suffix 用于给字段命名别名
# 目的在于防止主从表中有同名的字段,那么一般将主表的字段前面添加 m_,明细表的字段前面添加 d_
# 最终形成 main.iid as m_iid,detail.iid as d_iid
SET @prefix = 'm.';
SET @suffix = ' as m_';
SELECT group_concat(fieldname) fieldname
FROM (
SELECT 1 AS id,concat(@prefix,column_name,@suffix,column_name) AS fieldname,
column_comment AS comment
FROM information_schema.columns t1
WHERE table_schema='gsms' AND table_name='bill_detail'
) t2;
取有间隔符号的字符串指定位序的元素
# 其中第一个参数是原始字符串,第二个参数是间隔符号,第三个是位序
SELECT SUBSTRING_INDEX('7654,7698,7782,7788',',',1)
# 取第二个元素 010C1。第一次使用 SUBSTRING_INDEX 的位序2会获取到:0704-010C1
# 再次使用位序 -1 表示获取 0704-010C1 的最后一个元素
SELECT SUBSTRING_INDEX(SUBSTRING_INDEX('0704-010C1-0212-1','-',2),'-',-1) AS clientId;
以注释构建字段字符串
# 获取指定数据库指定名称的表字段,构成以英文逗号间隔的字符串
# 通过变量@prefix 设定字段所属表别名,通过变量 @suffix 设定字段别名
# 取字段注释中第一个英文逗号间隔开的第一个元素作为字段别名
# 最终得到的结果类似:...main.codeid as m-单据编号...
# 前面的 main. 表示拼接到目标 SQL 中要求表的别名是 main,后面的 m- 是为了防止主表和明细表的字段重复
# 最后的 单据编号 来自于字段的注释
SET @dbName = 'femis';
SET @tableName = 'orderdetail';
SET @prefix = 'detail.';
SET @suffix = ' d-';
SELECT group_concat(fieldname) fieldname
FROM (
SELECT 1 AS id,concat(@prefix,column_name,' as `',@suffix,SUBSTRING_INDEX(column_comment,',',1),'`') AS fieldname,
column_comment AS comment
FROM information_schema.columns t1
WHERE table_schema=@dbName AND table_name=@tableName
) t2;
将字段拼接为 JSON 对象
SET @dbName = 'femis';
SET @tableName = 'ordermain';
SET @prefix = '"';
SET @suffix = '":""';
SELECT GROUP_CONCAT(fieldname) fieldname
FROM (
SELECT 1 AS id,CONCAT(@prefix,column_name,@suffix) AS fieldname,
column_comment AS COMMENT
FROM information_schema.columns t1
WHERE table_schema=@dbName AND table_name=@tableName
) t2;
列转行,分割字符串
SET @mills = '朗迪印染,香山印染,港荣印染';
SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@mills,',',help_topic_id+1),',',-1) AS val
FROM mysql.help_topic
WHERE help_topic_id < LENGTH(@mills)-LENGTH(REPLACE(@mills,',',''))+1
设置数据库中所有表的字符集
# 下面的 femis 是数据库名称,设置该数据库下的所有表的字符集
SELECT CONCAT('ALTER TABLE ', table_name, ' CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;')
FROM information_schema.TABLES WHERE TABLE_SCHEMA = 'femis'
设置 varchar 字段的字符集
检测所有字段字符集不是 utf8mb4 的,构建出修改其为 utf8mb4 的SQL 语句
# 设置数据库下所有表所有类型为varchar 字段的字符集为 utf8mb4_general_ci
# 仅需要调整 femis 为目标数据库名称即可
# 2021年9月8日 14:18:49 增强了该方法,生成的SQL中会沿用字段原始定义中的非空、默认值
SELECT CONCAT('ALTER TABLE `', table_name, '` MODIFY `', column_name, '` ', DATA_TYPE,
'(', CHARACTER_MAXIMUM_LENGTH, ') CHARACTER SET UTF8 COLLATE utf8_general_ci',
(CASE WHEN IS_NULLABLE = 'NO' THEN ' NOT NULL' ELSE '' END),
(case when COLUMN_DEFAULT is null then '' else
case when COLUMN_DEFAULT='' then concat(' default ','\'\'') else concat(' default \'',COLUMN_DEFAULT,'\'') end end),
';') as defineSQL
FROM information_schema.COLUMNS
WHERE TABLE_SCHEMA = 'white_account_003'
AND DATA_TYPE = 'varchar'
AND
(
CHARACTER_SET_NAME != 'utf8mb4'
OR
COLLATION_NAME != 'utf8mb4_general_ci'
);
设置 varchar 字段默认值空字符串
# 设定指定数据库下的所有表的 varchar 类型的字段
# 生成多个SQL语句,用于为指定数据库下的所有表的所有 varchar 字段设置默认值
# 默认值为空字符串,要设置下面的参数 @dbName 为指定的数据库名称
DELIMITER $$
SET @dbName = 'gsms';
SELECT CONCAT('ALTER TABLE `', table_name, '` ALTER COLUMN `', column_name, '` ',' set default \'\'',
(CASE WHEN IS_NULLABLE = 'NO' THEN ' NOT NULL' ELSE '' END), ';') AS execSQL
FROM information_schema.COLUMNS
WHERE TABLE_SCHEMA = @dbName
AND DATA_TYPE = 'varchar'
AND TABLE_NAME='table_style' # 指定表名
# AND COLUMN_NAME='ctl_type' # 指定字段名称
;$$
DELIMITER ;
拷贝单据字段样式给序时表用
# 将单据字段样式数据拷贝给序时表使用,使用前缀 m_ 表示主表
# 前缀 d_ 表示明细表字段
insert INTO table_style
(table_name,field_name, text, seq, width_percent, visible, immutable,
bool_column, width_primeng_str, align_header, align_cell, tick_pipe, cn_pipe, access_pipe,
create_time, width_zorro, width_primeng, get_url, opts, date_pipe, date_formatter, ctl_type,
generate_formula, digit, statistics, tease, formula_seq, filter, display_field, use_formatter,
digit_formatter, data_type, default_value, filter_reqdata, debounce_time, debounce_field, edit_requrl,
edit_valuefield, edit_displayfield, array_field)
SELECT 'rptChroBill', concat('m_',field_name) as field_name, text, seq, width_percent, visible, immutable,
bool_column, width_primeng_str, align_header, align_cell, tick_pipe, cn_pipe, access_pipe,
create_time, width_zorro, width_primeng, get_url, opts, date_pipe, date_formatter, ctl_type,
generate_formula, digit, statistics, tease, formula_seq, filter, display_field, use_formatter,
digit_formatter, data_type, default_value, filter_reqdata, debounce_time, debounce_field, edit_requrl,
edit_valuefield, edit_displayfield, array_field
FROM table_style WHERE table_name='bill_main';
有固定分隔符的字符串中查找元素
使用 find_in_set 函数 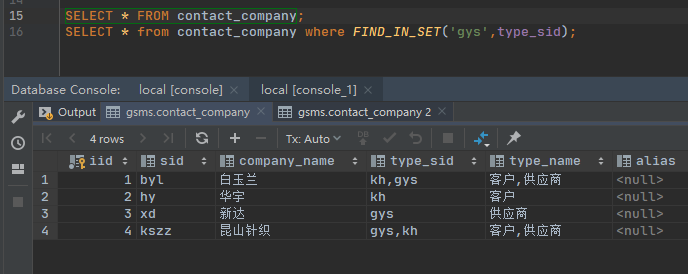
查询带有小写的字符串
SELECT * from product_file WHERE pf_coded REGEXP BINARY '[a-z]';
插入回车符、换行符
concat('字符串1',CHAR(10),CHAR(13),'字符串2')
递归
第一个演示案例
建表语句
DROP TABLE IF EXISTS `hr_dept`; CREATE TABLE `hr_dept` (
`deptId` bigint(200) NOT NULL,
`parent_id` bigint(200) DEFAULT NULL,
`dept_name` varchar(128) DEFAULT NULL,
`dept_code` varchar(24) DEFAULT NULL,
`dept_desc` varchar(512) DEFAULT NULL,
`dept_office_address` varchar(128) DEFAULT NULL,
`is_delete` varchar(255) DEFAULT NULL,
PRIMARY KEY (`deptId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
插入数据
INSERT INTO `hr_dept` VALUES ('1', '3', '行政部门', '100004', '管理公司事物', '江苏无锡菱湖大道', '1'); INSERT INTO `hr_dept` VALUES ('2', '3', '人事部门', '100003', '管理公司员工', '江苏无锡菱湖大道', '1'); INSERT INTO `hr_dept` VALUES ('3', '1', '测试部门', '100005', '前后台测试', '江苏无锡菱湖大道', '1'); INSERT INTO `hr_dept` VALUES ('4', '1', '移动应用部', '100006', '手机端开发', '江苏无锡菱湖大道', '1'); INSERT INTO `hr_dept` VALUES ('5', '1', '金融业务部门', '100007', '银行业务', '江苏无锡菱湖大道', '1'); INSERT INTO `hr_dept` VALUES ('6', '1', '战略规划部', '100001', '研发软件架构', '江苏无锡菱湖大道', '1'); INSERT INTO `hr_dept` VALUES ('7', '2', '应用开发部', '100002', 'PC端后台开发', '江苏无锡菱湖大道', '1'); INSERT INTO `hr_dept` VALUES ('8', '2', '咨询部', '100008', '接洽外部项目', '江苏无锡菱湖大道', '1'); INSERT INTO `hr_dept` VALUES ('9', '2', '华北交付中心', '100009', '调试软件项目', '江苏无锡菱湖大道', '1');
制作函数
create function getChildrenOrgOfHr(orgid INT)
returns varchar(4000)
BEGIN
DECLARE oTemp VARCHAR(4000); DECLARE oTempChild VARCHAR(4000); SET oTemp = ''; SET oTempChild = CAST(orgid AS CHAR); WHILE oTempChild IS NOT NULL DO
SET oTemp = CONCAT(oTemp,',',oTempChild); SELECT GROUP_CONCAT(deptId) INTO oTempChild FROM hr_dept WHERE FIND_IN_SET(parent_id,oTempChild) > 0; END WHILE; RETURN oTemp; END
获取指定节点的所有子节点
select * from hr_dept where FIND_IN_SET(deptId,getChildrenOrgOfHr(2));
第二个递归案例
创建表
DROP TABLE IF EXISTS vrv_org_tab;
CREATE TABLE vrv_org_tab (
id bigint(8) NOT NULL AUTO_INCREMENT,
org_name varchar(50) NOT NULL,
org_level int(4) NOT NULL DEFAULT '0',
org_parent_id bigint(8) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
UNIQUE KEY unique_org_name (org_name)
) ENGINE=InnoDB AUTO_INCREMENT=18 DEFAULT CHARSET=utf8;
插入数据
INSERT INTO vrv_org_tab VALUES ('1', '北信源', '1', '0');
INSERT INTO vrv_org_tab VALUES ('2', '北京', '2', '1');
INSERT INTO vrv_org_tab VALUES ('3', '南京', '2', '1');
INSERT INTO vrv_org_tab VALUES ('4', '武汉', '2', '1');
INSERT INTO vrv_org_tab VALUES ('5', '上海', '2', '1');
INSERT INTO vrv_org_tab VALUES ('6', '北京研发中心', '3', '2');
INSERT INTO vrv_org_tab VALUES ('7', '南京研发中心', '3', '3');
INSERT INTO vrv_org_tab VALUES ('8', '武汉研发中心', '3', '4');
INSERT INTO vrv_org_tab VALUES ('9', '上海研发中心', '3', '5');
INSERT INTO vrv_org_tab VALUES ('10', '北京EMM项目组', '4', '6');
INSERT INTO vrv_org_tab VALUES ('11', '北京linkdd项目组', '4', '6');
INSERT INTO vrv_org_tab VALUES ('12', '南京EMM项目组', '4', '7');
INSERT INTO vrv_org_tab VALUES ('13', '南京linkdd项目组', '4', '7');
INSERT INTO vrv_org_tab VALUES ('14', '武汉EMM项目组', '4', '8');
INSERT INTO vrv_org_tab VALUES ('15', '武汉linkdd项目组', '4', '8');
INSERT INTO vrv_org_tab VALUES ('16', '上海EMM项目组', '4', '9');
INSERT INTO vrv_org_tab VALUES ('17', '上海linkdd项目组', '4', '9');
根据主键查询所有子节点
create function getChildrenOrg(orgid INT)
returns varchar(4000)
BEGIN
DECLARE oTemp VARCHAR(4000);
DECLARE oTempChild VARCHAR(4000);
SET oTemp = '';
SET oTempChild = CAST(orgid AS CHAR);
WHILE oTempChild IS NOT NULL
DO
SET oTemp = CONCAT(oTemp,',',oTempChild);
SELECT GROUP_CONCAT(id) INTO oTempChild FROM vrv_org_tab WHERE FIND_IN_SET(org_parent_id,oTempChild) > 0;
END WHILE;
RETURN oTemp;
END
查询所有子节点使用演示
SELECT * FROM vrv_org_tab WHERE find_in_set(id,getChildrenOrg(2));
根据子节点查询所有父节点
SELECT id,org_name,org_level,org_parent_id
FROM (
SELECT
@r AS _id,
(SELECT @r := org_parent_id FROM vrv_org_tab WHERE id = _id) AS parent_id,
@l := @l + 1 AS lvl
FROM
(SELECT @r := 10, @l := 0) vars,# 左边括号中的 @r 的值为要查询的子节点的主键值
vrv_org_tab h
WHERE @r <> 0) T1
JOIN vrv_org_tab T2
ON T1._id = T2.id
ORDER BY id;
第三个案例
创建表
create table department
(
iid int auto_increment comment '自增主键' primary key,
sid varchar(100) default '' null comment '字符串编号',
sname varchar(100) default '' null comment '名称',
parent_sid varchar(100) default '' null comment '所属上级',
attr varchar(100) default '' null comment '属性:财务部门、制造部门',
tree_level int DEFAULT 0 null COMMENT '属性层级',
alias varchar(100) default '' null comment '别名',
scode varchar(100) default '' null comment '编码',
state int default 1 null comment '状态,默认1表示有效',
remark varchar(200) default '' null comment '备注',
print_count int default 0 null comment '打印次数',
seq int default 0 null comment '排序序号',
create_time datetime default CURRENT_TIMESTAMP null comment '创建时间,DB自动填充',
create_user varchar(100) default '' null comment '创建人',
last_update datetime default CURRENT_TIMESTAMP null comment '最后一次修改时间',
last_user varchar(100) default '' null comment '修改人'
)
comment '部门';
插入数据
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (1, '总经理', '', '翔轮', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:49:31', '', '2023-04-20 22:49:31', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (2, '人事总务部', '', '翔轮', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:49:31', '', '2023-04-20 22:49:31', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (3, '人事总务科', '', '人事总务部', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:49:31', '', '2023-04-20 22:49:31', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (4, '会计科', '', '人事总务部', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:49:58', '', '2023-04-20 22:49:58', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (5, '环境安全科', '', '人事总务部', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:49:58', '', '2023-04-20 22:49:58', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (6, '采购部', '', '翔轮', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:50:26', '', '2023-04-20 22:50:26', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (8, '采购科', '', '采购部', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:50:49', '', '2023-04-20 22:50:49', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (9, '生产管理部', '', '翔轮', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:51:08', '', '2023-04-20 22:51:08', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (10, '生产管理科', '', '生产管理部', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:51:30', '', '2023-04-20 22:51:30', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (11, '物流管理科', '', '生产管理部', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:51:30', '', '2023-04-20 22:51:30', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (12, '制造部', '', '翔轮', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:52:15', '', '2023-04-20 22:52:15', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (13, '制造科', '', '制造部', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:52:16', '', '2023-04-20 22:52:16', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (14, '设备管理科', '', '制造部', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:52:16', '', '2023-04-20 22:52:16', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (15, '品质保证部', '', '翔轮', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:52:16', '', '2023-04-20 22:52:16', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (16, '品质保证科', '', '品质保证部', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:52:36', '', '2023-04-20 22:52:36', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (17, '品质管理科', '', '品质保证部', '', 0, '', '', 1, '', 0, 0, '2023-04-20 22:52:36', '', '2023-04-20 22:52:36', '');
INSERT INTO showa2023.department (iid, sid, sname, parent_sid, attr, tree_level, alias, scode, state, remark, print_count, seq, create_time, create_user, last_update, last_user) VALUES (18, '翔轮', '', null, '', 0, '', '', 1, '', 0, 0, '2023-04-20 23:20:04', '', '2023-04-20 23:20:04', '');
查询指定节点的所有下级节点,包含自身
-- 单纯使用SQL递归 查询子节点 含自己
SELECT T2.level_, T3.*
FROM
(
SELECT @codes as _ids,
( SELECT @codes := GROUP_CONCAT(sid)
FROM department
WHERE FIND_IN_SET(parent_sid, @codes)
) as T1,
@l := @l+1 as level_
FROM department, (SELECT @codes :='人事总务部', @l := 0 ) T4
WHERE @codes IS NOT NULL
) T2, department T3
WHERE FIND_IN_SET(T3.sid, T2._ids)
ORDER BY level_, sid
;
查询指定节点的上级节点,不包含自身
SELECT T1.lvl,T2.* #lvl 跟查询无限下级的level一样
FROM (
SELECT
@r AS _id, #变量取个别名
(SELECT @r := parent_sid FROM department WHERE sid = _id limit 1) AS parent_id, #limit 1不加会报错,因为子查询不允许有多个,我当时没加在navicat是没问题,但是项目里就报错! parent_id 你的父级id的字段 sys_depart 你的表名
@l := @l + 1 AS lvl # T1.lvl 的来历,没用可以不要!或者感觉看不懂可以取消了
FROM
(SELECT @r := '会计科',@l := 0) vars, # @r := '9a61ebfffcc5430480fdd21245b1bf0c' 就是你要查的id,@l := 0 定义T1.lvl的初始值为0 没用可以取消不要
department h
WHERE parent_sid <> '') T1 #parent_id 你的父级id的字段 查询条件就是不等于0,可以根据自己业务做修改
JOIN department T2
ON T1.parent_id = T2.sid
ORDER BY T1.lvl;
查询指定节点的父节点,包含自身
SELECT T3.*
-- 层级需要
-- ,T2.level_
FROM(
SELECT @code as _code,
(SELECT @code := GROUP_CONCAT(parent_sid)
FROM department
WHERE FIND_IN_SET(sid,@code)
) as T1
-- 层级需要
,@level := @level+1 as level_
FROM department,
(SELECT @code := '会计科'
-- 层级需要
,@level := -1
) T4
WHERE @code IS NOT NULL
) T2, department T3
WHERE FIND_IN_SET(T3.sid, T2._code)
ORDER BY level_;
多表联合修改数据
UPDATE user_weixin a
JOIN (
SELECT * from user_weixin WHERE id = @wx_auto_id_source
) b
SET a.is_dev = b.is_dev,
a.status = b.status,a.check_permission=b.check_permission,
a.receive = b.receive, a.receive_process = b.receive_process,
a.receive_bp = b.receive_bp, a.receive_cp=b.receive_cp,
a.user_password = b.user_password,a.user_danwei = b.user_danwei,
a.user_sex = b.user_sex,a.tip = b.tip,a.user_img = b.user_img,a.user_phone = b.user_phone,
a.xiaochengxu_name = b.xiaochengxu_name,a.is_master = b.is_master
WHERE a.id = @wx_auto_id_target
分组与排序
无分组自定义序号
select @rownum:=@rownum+1 as autoSeq,
sid,pid,oprimary,seq
from singlechoice,(select @rownum:=0) r
order by pid,sid
单字段分组
# 下面的a表必须先按照预想的效果排序
# 表中的数据可能存在多个表的字段穿插的情况
select (@i := case when @tableName=a.tablename then @i + 1 else 1 end ) as rowIndex,
a.*,(@tableName:=a.tablename)
from (
SELECT * FROM tablestyle ORDER BY tablename,iid
) a,
(select @i:=0,@tableName:='') as t
group by tablename,fieldname
order by tablename,(@i := case when @tableName=a.tablename then @i + 1 else 1 end )
多字段分组
select (@i := case when @tableName=concat(a.dbname,a.tablename) then @i + 1 else 1 end ) as rowIndex,
a.*,(@tableName:=concat(a.dbname,a.tablename)) as temp
from tablestyle a,(select @i:=0,@tableName:='') as t
group by dbname,tablename,fieldname
order by dbname,tablename,(@i := case when @tableName=concat(a.dbname,a.tablename) then @i + 1 else 1 end )
win 系统忘记密码
- 在配置文件 C:\ProgramData\MySQL\MySQL Server 5.7\my.ini 的项目 mysqld 下添加:skip-grant-tables
- 重启 MYSQL 服务,使用 datagrip 连接服务器时不需要密码即可连接
- 在 datagrip 中选中 mysql 数据库执行命令
update user set authentication_string=password('chanchaw') where user='root';
填充到指定长度
DELIMITER $$;
CREATE FUNCTION fill2Length(noString VARCHAR(500),len INT,isFront bool,symbol VARCHAR(10))
RETURNS VARCHAR(500)
BEGIN
if length(noString) >= len
then return noString;
end if;
set @qty = len - length(noString);
set @i = 0;
set @filler = '';
while @i < @qty do
set @filler = concat(@filler,symbol);
set @i=@i+1;
end while;
set @ret = '';
if isFront = true then
set @ret = concat(@filler,noString);
else
set @ret = concat(noString,@filler);
end if;
RETURN @ret;
END $$;
DELIMITER ;
# select fill2Length('3333',3,true,'0') as aa;
# 传入数据已经超过指定的长度3,则直接返回 3333
# select fill2Length('11',3,true,'0') as aa;
# 返回 011
select into
mysql 不同于 sql server ,后者有 select into ,前者要先创建好同架构的表然后通过 insert into 插入数据
CREATE TABLE mioloss LIKE mioe;
INSERT INTO mioloss
SELECT *
FROM mioe
WHERE `存货编码` NOT IN (SELECT `存货编码` FROM mios);
SELECT * FROM mioloss;
创建数据库
CREATE DATABASE IF NOT EXISTS myDatabase DEFAULT CHARSET utf8mb4 COLLATE utf8mb4_general_ci;
生成序号字段
无分组 - 全部数据排序
SELECT
@r:= @r + 1 AS rowNum,
a.*
FROM
tmp_mytest a,( SELECT @r:= 0 ) b
分组序号
SELECT
@r:= case when @type=a.type then @r+1 else 1 end as rowNum,
@type:=a.type as type,
a.id
from
tmp_mytest a ,(select @r:=0 ,@type:='') b;
函数
填充重复字符
# m_oStr - 原始字符串
# m_TNumber - 填充至目标长度
# m_FillStr - 填充的字符,一般为0
# m_PreOrBack - 0在原字符串前面填充重复字符,1在后面填充
create definer = root@`%` function FillRepeat(m_oStr varchar(100), m_TNumber int, m_FillStr varchar(100), m_PreOrBack int) returns varchar(100)
BEGIN
Declare i int;
Declare j int;
Declare m_Result varchar(100);
Declare m_FillStrs varchar(100);
set j=1;
set m_FillStrs='';
if CHAR_LENGTH(m_oStr)>=m_TNumber THEN
#如果原始字串的长度大于等于目标长度了,则直接返回原始字串
set m_Result=m_oStr;
ELSE
#否则才需要做填充的工作
set i=m_TNumber-CHAR_LENGTH(m_oStr);
while j<=i do
set m_FillStrs=m_FillStrs + m_FillStr;
set j=j+1;
end while;
if m_PreOrBack=0 then
set m_Result=m_FillStrs + m_oStr;
else
set m_Result=m_oStr + m_FillStrs;
end if;
END if;
RETURN m_Result;
END;