数据类型
stringstream
依赖
必须包含下面头文件
#include <sstream>
打印到控制台
cout << m_ss.str() << endl;
转CString
CString m_msg = L"";// 绑定到MFC edit control 的变量
m_msg = m_ss.str().c_str();
UpdateData(FALSE);// 更新显示到UI
案例
// 最简单案例
#include <sstream>
::stringstream m_ss;
m_ss<<"函数printInfo中打印信息,窗口句柄";
cout << m_ss.str() << endl;
数组
// 声明 int 类型数组
int addrArr[3] = {0x006A9EC0, 0x768, 0x5560};// 阳光地址,依次是:基址,偏移01,偏移02
字符串
概述
cpp 环境下区分字符串为多字节字符串和 utf8 字符串,使用 string 声明一个字符串时要求初始化的格式是 string aa = L"ABC" 多字节字符串表现为 char aa[] = ""; 一般出线在游戏中角色的中文名,要在外挂程序中(外挂的控制台)正确显示该中文名称需要将宽字符转换为多字节字符串后打印到控制台上
多字节和宽字符
概述
在C++中,宽字符是指使用 wchar_t 类型表示的字符。宽字符可以表示比普通字符更多的字符集,因此可以用来表示非西方语言中的字符。普通字符类型是 char,通常是一个字节,而宽字符通常是两个或多个字节。在 C++ 中,使用 L 前缀可以创建宽字符字面量或常量。例如:
wchar_t wide_char = L'A'; // 定义单个宽字符
const wchar_t* wide_string = L"This is a wide string"; // 定义宽字符串
宽字符通常用于多语言应用程序或在需要支持大量字符的情况下,一般的各个国家自己制定的编码,例如中国大陆的 GBK,GB18030,GB2312 和台湾的 Big5 以及国际通用的 UTF8编码都是针对多字节字符串,宽字符指的是由统一码联盟制定的 Unicode 编码方案收录的字符,使用 4 个字节来表示一个字符。可参见 精述字符编码
长度
在C++中,宽字符的长度取决于编译器和操作系统。通常,宽字符使用 wchar_t 类型表示,该类型是一个有符号整数类型,用于表示宽字符。在大多数操作系统上,wchar_t 是两个字节长,因此宽字符的长度通常是两个字节。但是,有些编译器和操作系统使用四个字节来表示宽字符。在这种情况下,宽字符的长度为四个字节。 因此,如果要确定宽字符的长度,应使用 sizeof 运算符来检查 wchar_t 类型的大小。例如:
std::cout << "Size of wchar_t: " << sizeof(wchar_t) << " bytes" << std::endl;
这将输出 wchar_t 类型的大小,以字节为单位。
声明与打印
const char* multBytes = "警幻仙子暗提点.mp3";// 多字节字符串
const wchar_t* wideCharacter = L"警幻仙子暗提点.mp3";// 宽字符串
std::wstring wideString = L"031 第31集 警幻仙子暗提点.mp3";// 也是宽字符
std::cout << "char* 多字节字符串【" << multBytes << "】的长度是:" << strlen(multBytes) << std::endl;
setlocale(LC_ALL, "chs");
wprintf(L"wprintf 打印 wchar_t* 宽字符:【%s】,的长度是:%d\n", wideCharacter, wcslen(wideCharacter));
wprintf_s(L"wprintf_s 打印 wchar_t* 宽字符:【%s】,的长度是:%d\n", wideCharacter, wcslen(wideCharacter));
wprintf_s(L"wprintf_s 打印 wstring 宽字符:【%s】,长度是:%d\n", wideString, wideString.length());
std::wcout << L"wcout 打印 wideString 宽字符【" << wideString.c_str() << L"】,长度是:" << wideString.length() << std::endl;
std::wstring a1 = wideString.substr(0, 3);
std::wstring a2 = wideString.substr(0, 4);
std::wstring a3 = wideString.substr(0, 5);
std::wcout << L"【" << wideString.c_str() << L"】依次截取长度345的结果是:【" << a1.c_str() << L"】,【" << a2.c_str() << L"】,【" << a3.c_str() << L"】" << std::endl;
std::wstring a4 = wideString.substr(4);
std::wcout << L"原字符串【" << wideString.c_str() << L"】从位序4开始截取得到的字符串是:【" << a4.c_str() << L"】" << std::endl;
/* 上面打印的结果是:
char* 多字节字符串【警幻仙子暗提点.mp3】的长度是:18
wprintf 打印 wchar_t* 宽字符:【警幻仙子暗提点.mp3】,的长度是:11
wprintf_s 打印 wchar_t* 宽字符:【警幻仙子暗提点.mp3】,的长度是:11
wprintf_s 打印 wstring 宽字符:【狴?】,长度是:11237720
wcout 打印 wideString 宽字符【031 第31集 警幻仙子暗提点.mp3】,长度是:20
【031 第31集 警幻仙子暗提点.mp3】依次截取长度345的结果是:【031】,【031 】,【031 第】
原字符串【031 第31集 警幻仙子暗提点.mp3】从位序4开始截取得到的字符串是:【第31集 警幻仙子暗提点.mp3】
*/
互相转换
C/C++中char表示多字节字符串,wchar_t表示宽字符串,由于编码不同,所以在char和wchar_t之间无法使用强制类型转换。考察如下程序:
#include <iostream>
using namespace std;
int main() {
const wchar_t* str=L"ABC我们";
char* s=(char*)str;
cout<<s<<endl;
}
输出结果出错:只输出 A。经过强制类型转换,s 指向了宽字符串,字符串数据没有发生任何变化,只是用多字节字符字符编码重新对它进行解释,输出的结果自然是错误的。使用 C/C++ 实现多字节字符串与宽字符串的相互转换,需要使用 C 标准库函数 mbstowcs 和 wcstombs。
//将多字节编码转换为宽字节编码
size_t mbstowcs (wchar_t* dest, const char* src, size_t max);
//将宽字节编码转换为多字节编码
size_t wcstombs (char* dest, const wchar_t* src, size_t max);
这两个函数,转换过程中受到系统编码类型的影响,需要通过设置来设定转换前和转换后的编码类型。通过函数setlocale进行系统编码的设置。Linux下输入命名locale -a查看系统支持的编码类型。
andy@andy-linux:~$ locale -a
c
en_ag
en_au.utf8
en_bw.utf8
en_ca.utf8
en_dk.utf8
en_gb.utf8
en_hk.utf8
en_ie.utf8
en_in
en_ng
en_nz.utf8
en_ph.utf8
en_sg.utf8
en_us.utf8
en_za.utf8
en_zw.utf8
posix
zh_cn.gb18030
zh_cn.gbk
zh_cn.utf8
zh_hk.utf8
zh_sg.utf8
zh_tw.utf8
下面是多字节和宽字符相互转换的代码实现:
#include <locale.h>
#include <stdlib.h>
/********************************************
*@brief:不同编码字符串转Unicode
*@pram:cpMbs:多字节字符串;wcpWcs:宽字符串;wcsBuffLen:宽字符串缓冲区大小(单位宽字符);dEncodeType:多字节字符串编码类型,0:GBK,1:UTF8
*@ret:-1:出错;>=0:转换成功的字符个数
*@birth:created by dablelv on 20170804
*@revision:
********************************************/
int mbs2wcs(const char* cpMbs,wchar_t* wcpWcs,int wcsBuffLen,int dEncodeType) {
if(NULL==cpMbs || 0==strlen(cpMbs)) return 0;
// GBK 转 Unicode
if(0==dEncodeType) {
if(NULL==setlocale(LC_ALL,"zh_CN.gbk")) // 设置转换为unicode前的编码为gbk编码
return -1;
}
// UTF8 转 Unicode
if(1==dEncodeType) {
if(NULL==setlocale(LC_ALL,"zh_CN.utf8")) // 设置转换为unicode前的编码为utf8编码
return -1;
}
int unicodeCNum=mbstowcs(NULL,cpMbs,0); // 计算待转换的字符数
if(unicodeCNum<=0||unicodeCNum>=wcsBuffLen) { // 转换失败或宽字符串缓冲区大小不足
return -1;
}
unicodeCNum=mbstowcs(wcpWcs,cpMbs,wcsBuffLen-1); // 进行转换,wcsBuffLen-1表示最大待转换的宽字符数,即宽字符串缓冲区大小
return unicodeCNum;
}
/********************************************
*@brief:Unicode转指定编码字符串
*@pram:wcpWcs:宽字符串;cpMbs:多字节字符串缓冲区;dBuffLen:多字节字符串缓冲区大小(单位字节);dEncodeType:多字节字符串编码类型,0:GBK,1:UTF8
*@ret:-1:出错;>=0:转换成功的字节个数
*@birth:created by dablelv on 20180114
*@revision:
********************************************/
int wcs2mbs(const wchar_t* wcpWcs,char* cpMbs,int dBuffLen,int dEncodeType) {
if(wcpWcs==NULL || wcslen(wcpWcs)==0) {
return 0;
}
//Unicode转GBK
if(0==dEncodeType) {
if(NULL==setlocale(LC_ALL,"zh_CN.gbk")) //设置目标字符串编码为gbk编码
return -1;
}
//Unicode转UTF8
if(1==dEncodeType) {
if(NULL==setlocale(LC_ALL,"zh_CN.utf8")) //设置目标字符串编码为utf8编码
return -1;
}
int dResultByteNum=wcstombs(NULL,wcpWcs,0); // 计算待转换的字节数
if(dResultByteNum<=0 || dResultByteNum>=dBuffLen) {
return -1; // 转换失败或多字节字符串缓冲区大小不足
}
wcstombs(cpMbs,wcpWcs,dBuffLen-1);
return dResultByteNum;
}
测试代码采用 utf8 编码:
int main(int argc,char* argv[]) {
char* cpMbs="I believe 中国民族将实现伟大复兴";
wchar_t* wcpWcs=L"I believe 中国民族将实现伟大复兴";
char cBuff[1024]={'\0'};
wchar_t wcBuff[1024]={L'\0'};
// UTF8 多字节字符串转换为 Unicode 字符串
int ret=mbs2wcs(cpMbs,wcBuff,1024,1);
// 转换后字符串与字符串长度
printf("返回值:%d,字符数:%d,宽字符串:%S\n",ret,wcslen(wcBuff),wcBuff); //printf使用%ls也可以输出宽字符串
// Unicode 字符串转换为 UTF8 多字节字符串
ret=wcs2mbs(wcpWcs,cBuff,1024,1);
// 转换后字符串与字符串字节数
printf("返回值:%d,字符串字节数:%d,字符串:%s\n",ret,strlen(cBuff),cBuff);
}
// 下面是输出结果
// 返回值:21,字符数:21,宽字符串:I believe 中国民族将实现伟大复兴
// 返回值:43,字符串字节数:43,字符串:I believe 中国民族将实现伟大复兴
注意:请不要同时使用 printf() 与 wprintf(),否则会出现后者无法输出的奇怪现象。该现象的解释与解决办法参见博文 C printf() 详解之终极无惑
除了利用标准库函数解决字符编码的转换问题,还可以利用特定操作系统下提供的函数。例如,利用Windows API实现字符编码的转换
#include <windows.h>
#include <iostream>
using namespace std;
int main() {
const wchar_t* ws=L"测试字符串";
const char* ss="ABC我们";
// 宽字符串转换为多字节字符串
int bufSize = WideCharToMultiByte(CP_ACP, NULL, ws, -1, NULL, 0, NULL, FALSE);
cout << bufSize << endl;
char *sp = new char[bufSize];
WideCharToMultiByte(CP_ACP, NULL, ws, -1, sp, bufSize, NULL, FALSE);
cout << sp << endl;
// 宽字符串转换为多字节字符串
bufSize = MultiByteToWideChar(CP_ACP, 0, ss, -1, NULL, 0);
cout << bufSize << endl;
wchar_t* wp = new wchar_t[bufSize];
MultiByteToWideChar(CP_ACP, 0, ss, -1, wp, bufSize);
wcout.imbue(locale("chs"));
wcout<< wp <<endl;
}
/*
输出结果是:
11
测试字符串
6
ABC我们
*/
其中函数 int bufSize=WideCharToMultiByte(CP_ACP,NULL,ws,-1,NULL,0,NULL,FALSE); 是用来获取宽字符串转换成多字节字符串所占据的空间大小(单位字节),这是将第5个参数设置为NULL达到的效果。同样,函数调用 bufSize=MultiByteToWideChar(CP_ACP,0,ss,-1,NULL,0); 是用来获取多字节字符串转换成宽字节字符串后所占用空间的大小(单位宽字符个数),这是将第5个参数设置为NULL之后达到的效果。下面讲解两个关键函数:
/*
标准C函数:WideCharToMultiByte
函数功能:将宽字符串转换成多字节字符串
头文件:< windows.h>
函数原型:
int WINAPI WideCharToMultiByte(
_In_ UINT CodePage,
_In_ DWORD dwFlags,
_In_NLS_string_(cchWideChar) LPCWCH lpWideCharStr,
_In_ int cchWideChar,
_Out_writes_bytes_to_opt_(cbMultiByte, return) LPSTR lpMultiByteStr,
_In_ int cbMultiByte,
_In_opt_ LPCCH lpDefaultChar,
_Out_opt_ LPBOOL lpUsedDefaultChar
);
参数详解:
CodePage:指定执行转换的代码页字符集,可以为操作系统已安装或有效的任何代码页字符集,也可以指定其为下面的任意一值:CP_ACP:ANSI代码页;CP_MACCP:Macintosh代码页;CP_OEMCP:OEM代码页;CP_SYMBOL:符号代码页;CP_THREAD_ACP:当前线程ANSI代码页;CP_UTF7:使用UTF-7转换;CP_UTF8:使用UTF-8转换。使用最多的就是CP_ACP和CP_UTF8;
dwFlags:指定如何处理没有转换成功的字符,也可以不设此参数(设置为0),函数会运行的更快一些。对于UTF-8,dwflags必须为0或者WC_ERR_INVALID_CHARS,否则函数将执行失败并设置错误码ERROR_INVALID_FLAGS,可以调用GetLastError获得错误码;
lpWideCharStr:待转换为宽字符串;
cchWideChar:待转换的宽字符串的长度(字符个数),-1表示转换到字符串结尾;
lpMultiByteStr:转换后目的字符串缓冲区;
cbMultiByte:目的字符串缓冲区大小(单位字节)。如果设置为0,函数将返回所需缓冲区大小而忽略lpMultiByteStr;
lpDefaultChar:指向字符的指针,在指定编码里找不到相应字符时使用此字符作为默认字符替代。如果为NULL,则使用系统默认字符。使用dwFlags时不能使用此参数,否则报ERROR_INVLID_PARAMETER错误;
lpUsedDefaultChar:开关变量的指针,表明是否使用过默认字符。对于要求此参数为NULL的dwflags而使用此参数,函数将失败返回,并设置错误码ERROR_INVLID_PARAMETER。lpDefaultChar和lpUsedDefaultChar都设为NULL,函数会更快一些。
函数返回值:如果函数运行成功,并且cbMultiByte不为零,返回值是由lpMultiByteStr指向的缓冲区中写入的字节数;如果函数运行成功,并且cbMultiByte为零,返回值是存放目的字符串缓冲区所必需的字节数。如果函数运行失败,返回值为零。若想获得更多错误信息,请调用GetLastError函数。
*/
// =====================================================================
/*
标准C函数:MultiByteToWideChar
函数功能:多字节字符串到款字节字符串的转换
头文件:<windows.h>
函数原型:
int WINAPI MultiByteToWideChar(
_In_ UINT CodePage,
_In_ DWORD dwFlags,
_In_NLS_string_(cbMultiByte) LPCCH lpMultiByteStr,
_In_ int cbMultiByte,
_Out_writes_to_opt_(cchWideChar, return) LPWSTR lpWideCharStr,
_In_ int cchWideChar
);
参数详解:
CodePage:同上;
dwFlags:指定是否转换成预制字符或合成的宽字符,是否使用象形文字替代控制字符,以及如何处理无效字符。对于UTF-8,dwflags必须为0或者WC_ERR_INVALID_CHARS,否则函数将执行失败并设置错误码ERROR_INVALID_FLAGS,可以调用GetLastError获得错误码;
lpMultiByteStr:多字节字符串;
cbMultiByte:待转换的多字节字符串长度,-1表示转换到字符串结尾;
lpWideCharStr:存放转换后的宽字符串缓冲;
cchWideChar:宽字符串缓冲的大小(单位字符数)。
返回值:如果函数运行成功,并且cchWideChar不为零,返回值是由 lpWideCharStr指向的缓冲区中写入的字符数;如果函数运行成功,并且cchWideChar为零,返回值是存放目的字符串缓冲区所必需的字符数。如果函数运行失败,返回值为零。若想获得更多错误信息,请调用GetLastError函数。
*/
string类
要使用 string 类,需要如下引用
#include "string"
using namespace std;
CString
类型 CString 是宽字符,硬编码赋值时要求左边要有大写的L,例如:CString aa = L"abcd中国",拼接其他数值类型的数据时可采用下面的方式
// 使用成员函数拼接字符串 - 宽字符类型
CString sunVal01 = L"";
sunVal01.Format(_T("阳光值:%d"), (void*)sunVal);
拼接的类型仍然是 CString 的话使用 + 即可。
声明变量
char windowClassName[] = "ConsoleWindowClass";
声明常量
const char *roleName="player";
拼接字符串
拼接HANDLE类型到CString
// 函数将HANDLE转换为CString,并拼接到另一个CString上
CString ConcatenateHandleToString(HANDLE handle, CString& baseString) {
// 获取HANDLE的值,这里假设它是一个指针类型
//TCHAR handleStr[sizeof(handle)]; // 假设HANDLE可以用20个字符表示
TCHAR handleStr[50];
_stprintf_s(handleStr, _T("%p"), handle);
// 拼接字符串
baseString += handleStr;
return baseString;
}
// 调用方法,注意是在变量 editorText 原来内容的后面追加内容,不是覆盖
ConcatenateHandleToString(gameProcessHandle, editorText);
打印的方式拼接
下面代码中的第三种更方便使用
#include <iostream>
#include <string>
#include <cstdlib>
#include <sstream>
#include <cstring>
using namespace std;
//第一种:C风格的转化(以前一直喜欢的 sprintf 功能强大)
void test()
{
char *s = "dong";
int a = 52;
float b = .1314;
char *buf = new char[strlen(s) + sizeof(a) + 1];
sprintf(buf, "%s%d%.4f", s, a, b);
printf("%s\n", buf);
}
//第二种:半C半C++风格
void test1()
{
string s = "dong";
int a = 520;
char *buf = new char[10];//2147483647 int最大值
_itoa(a, buf, 10); //itoa虽然可以转化为各种进制,但是注意不能是float或者double
cout << s + buf << " | ";
_itoa(a, buf, 16);
cout << s + buf << endl;
}
//第三种:纯C++风格
void test2()
{
string s = "陈明东";
int a = 52;
double b = .1314;
ostringstream oss;
oss << s << a << b;
cout << oss.str() << endl;
}
//第四种:C++11新特性
void test3()
{
int a = 520;
float b = 5.20;
string str = "dong";
string res = str + to_string(a);
cout << res << endl;
res = str + to_string(b);
res.resize(8);
cout << res << endl;
}
int main()
{
test();
test1();
test2();
test3();
return 0;
}
日期时间
cpp中获取当前日期时间的函数在常用版本中的不同使用看下图 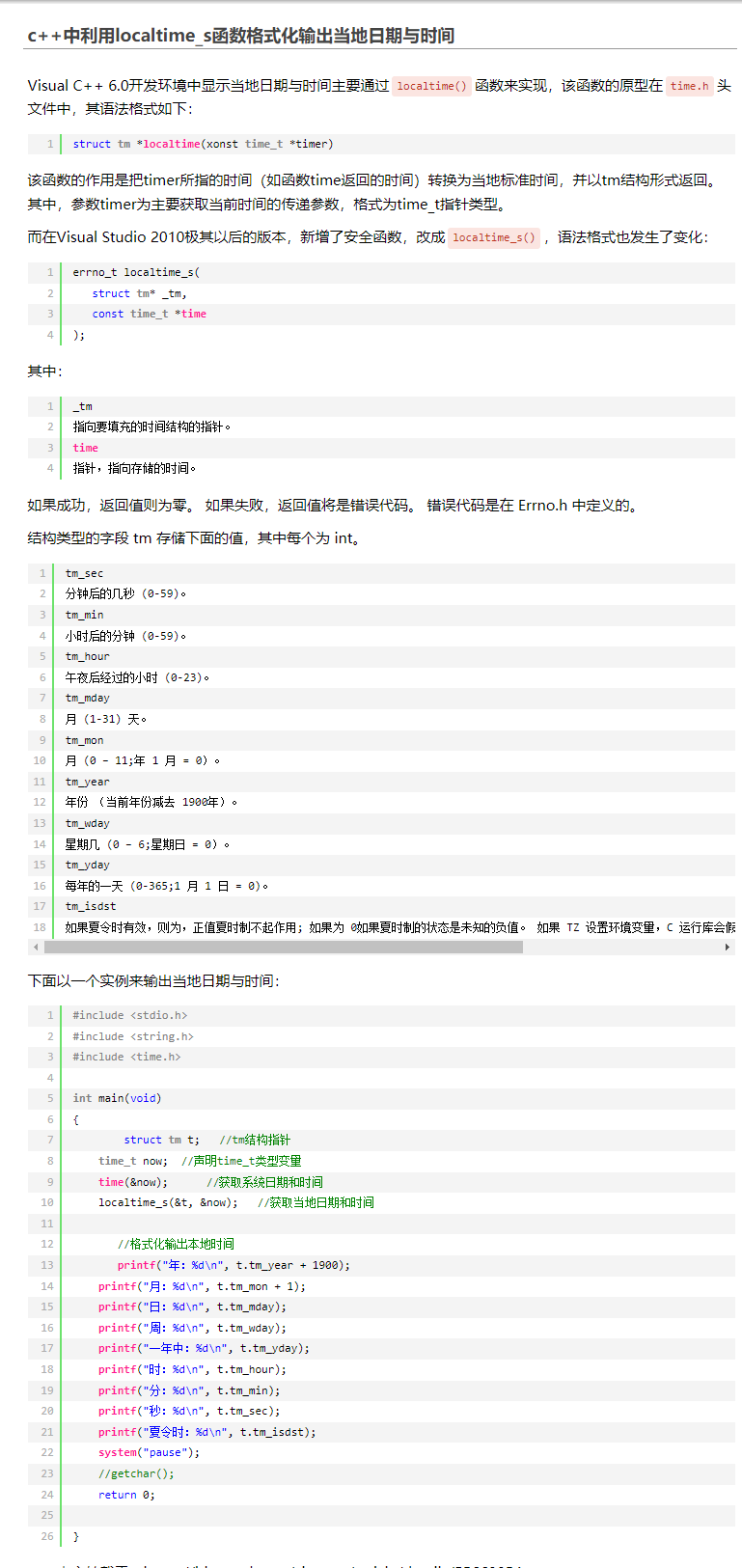 自己封装的工具源码:
自己封装的工具源码:
// 日期时间函数用到
#include "pch.h"
#include <stdio.h>
#include <time.h>
#include <sstream>
#include <iostream>
using namespace std;
string getNowStr() {
struct tm t; //tm结构指针
time_t now; //声明time_t类型变量
time(&now); //获取系统日期和时间
localtime_s(&t, &now); //获取当地日期和时间
//格式化输出本地时间
int year = t.tm_year + 1900;
int month = t.tm_mon + 1;
/*printf("年:%d\n", year);
printf("月:%d\n", month);
printf("日:%d\n", t.tm_mday);
printf("周:%d\n", t.tm_wday);
printf("一年中:%d\n", t.tm_yday);
printf("时:%d\n", t.tm_hour);
printf("分:%d\n", t.tm_min);
printf("秒:%d\n", t.tm_sec);
printf("夏令时:%d\n", t.tm_isdst);*/
ostringstream oss;
// 将数字和字符拼接起来
oss << year << "年" << month << "月" << t.tm_mday << "日" << " " << t.tm_hour << ":" << t.tm_min << ":" << t.tm_sec;
return oss.str();
}
在兄弟文件中先声明函数签名再使用 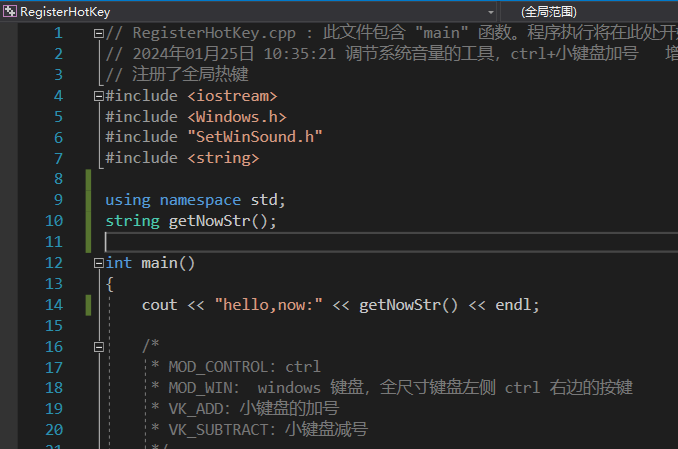
非基础类型
UINT_PTR
一般函数地址和返回值使用该类型,例如下面代码,通过 printf 打印时指定的数据类型在下面代码的最后
const char* roleName="player";
UINT_PTR retVal = 0;// 用于接收返回值
UINT_PTR funcAddr = 0x60C1F0;// 调用的call的起始地址(函数的起始地址)
__asm {
lea eax,roleName
push eax
call funcAddr
add esp,4 // 外平栈
mov retVal,eax // 返回值赋值给cpp变量
}
printf("返回值:%p\r\n", retVal);
该类型转换为 LPVOID 可通过强制类型转换
void addSunVal1000() {
UINT_PTR sunVal = GetSunVal();
sunVal += 1000;
// GetSunAddr 返回的类型是 UINT_PTR
LPVOID sunAddr = (LPVOID)GetSunAddr();
write4(gameProcessHandle, sunAddr, (LPCVOID)sunVal);
}