interviewBible
final
static
概述
static 修饰的是类变量,没有 static 则是成员变量,两者的区别:
1、两个变量的生命周期不同
成员变量随着对象的创建而存在,随着对象的回收而释放 静态变量随着类的加载而存在,随着类的消失而消失。
2、调用方式不同
成员变量只能被对象调用 静态变量可以被对象调用,还可以被类名调用。
3、别名不同
成员变量也称为实例变量 静态变量也称为类变量。
4、数据存储位置不同
成员变量存储在堆内存的对象中,所以也叫对象的特有数据 静态变量数据存储在方法区(共享数据区)的静态区,所以也叫对象的共享数据。
类的成员变量是 static 对象
类的成员变量被 static 修饰,则该属性是类属性,不是对象属性(所有对象共享该属性,一个对象修改了该属性会立即在其他对象中体现出来) 延伸出来,如果 static 修饰的成员变量是另外一个类的对象(非基本类型),则所有对象的该属性同样共享该对象 相反,没有 static 则属性是每个对象独占的,即修改 A 对象的该属性不影响 B 对象的该属性
// 下面是两个用于测试的类
public class DatetimeUtils {
public static UUID uuid = new UUID();
...
}
public class UUID {
public String test = "";
...
}
// 测试类的静态变量的共享效果
public static void main(String[] args) {
DatetimeUtils e01 = new DatetimeUtils();
DatetimeUtils e02 = new DatetimeUtils();
e01.uuid.test = "cc";
System.out.println("e01:" + e01.uuid.test + "\n" + "e02:" + e02.uuid.test);
}
// 打印效果
e01:cc
e02:cc
String str = new String(“hello“) 和 String str = “hello“
- 对象的创建方式不同。第一种方式是使用了String类的构造方法,新建了一个String对象,其存储在堆中 第二种方式是字面量赋值,其存储在常量池中 常量池中的字符串不会重复,比 new String() 会更少使用内存 使用字面量方式多次创建同一个字符串,指向的是同一个内存地址 而使用 new String() 创建的字符串不管字符串内容是否相同,每次都是新地址
- 由于常量池中的对象会被JVM自动进行管理和回收,所以在使用字符串字面量创建字符串对象时,能够提高Java应用程序的性能和效率。
测试代码:
public static void main(String[] args) {
String cStr01 = "aaa";
String cStr02 = "aaa";
String heapStr01 = new String("aaa");
String heapStr02 = new String("aaa");
System.out.println("cStr01 = cStr02:" + (cStr01 == cStr02 ? true : false));
System.out.println("cStr01.equalsIgnoreCase(cStr02):" + (cStr01.equalsIgnoreCase(cStr02) ? true : false));
System.out.println("cStr01 = heapStr01:" + (cStr01 == heapStr01 ? true : false));
System.out.println("cStr01.equalsIgnoreCase(heapStr01):" + (cStr01.equalsIgnoreCase(heapStr01) ? true : false));
System.out.println("heapStr01 = heapStr02:" + (heapStr01 == heapStr02 ? true : false));
System.out.println("heapStr01.equalsIgnoreCase(heapStr02):" + (heapStr01.equalsIgnoreCase(heapStr02) ? true : false));
/* 打印结果:
cStr01 = cStr02:true
cStr01.equalsIgnoreCase(cStr02):true
cStr01 = heapStr01:false
cStr01.equalsIgnoreCase(heapStr01):true
heapStr01 = heapStr02:false
heapStr01.equalsIgnoreCase(heapStr02):true
*/
}
HashMap扩容机制
HashMap 是 java 中的一个散列表实现,它将键值对映射到一个桶数组中,并且通过哈希值快速定位每个键值对所在位置,当 HashMap 中元素增加到一定阈值时它会自动扩容,以保证散列表的负载因子在一个可接受的范围内,从而提高其性能。其自动扩容机制如下:
- 当 HashMap 的元素数量超过其容量(初始默认16,第一次 put 时生成)和负载因子(也叫做加载因子)(默认为0.75)的乘积时会触发扩容 阈值 = 容量 * 加载因子,那么默认阈值=12,即 put 第13个元素时 HashMap 会自动扩容
- 通过 HashMap 类的 resize 方法扩容,该操作会创建一个新的桶数组,容量为原来的两倍,并将所有键值对重新分配到新的桶数组中
- 重新分配时会根据键的哈希值和新桶数组的长度计算出该键值对在新桶数组中的位置,并将其插入到该位置中
- 在插入时如果该位置已经存在其他键值对则使用链表或者红黑树来处理冲突
- 扩容对元素迁移时是两层循环,外层遍历数组的每个桶,内层遍历桶中的每个键值对,重新计算 hash 值来找到新数组中的位置,以头插法插入,所以新旧链表元素的位置可能不同
- 最大容量230,当容量超过230时就不再扩大,阈值变为 231-1
- java1.8+,桶上链表长度大于等于8时,链表转化为红黑树
- java1.8+,桶上的红黑树大小小于等于6时,红黑树转化成链表
- java1.8+,只有当数组容量大于64时,链表才会转化成红黑树
下面是通过反射获取 HashMap 的容量和负载因子的方法
import java.lang.reflect.Field;
import java.util.HashMap;
public class HashMapDemo {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
map.put("0","0");
System.out.println("Initial Size: " + map.size());
System.out.println("Initial threshold: " + getThreshold(map));
System.out.println("Initial Capacity: " + getCapacity(map));
System.out.println("loadFactor: " + getLoadFactor(map));
for (int i = 1; i < 13; i++) {
map.put("key" + i, "value" + i);
}
System.out.println("Size: " + map.size());
System.out.println("threshold after expansion: " + getThreshold(map));
System.out.println("Capacity after expansion: " + getCapacity(map));
System.out.println("loadFactor after expansion: " + getLoadFactor(map));
}
//hashMap阈值
private static int getThreshold(HashMap<?, ?> map) {
try {
Field threshold = HashMap.class.getDeclaredField("threshold");
threshold.setAccessible(true);
return (int) threshold.get(map);
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
return -1;
}
}
// 获取HashMap的负载因子
private static float getLoadFactor(HashMap map) {
try {
Field field = HashMap.class.getDeclaredField("loadFactor");
field.setAccessible(true);
return (float) field.get(map);
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
return -1.0f;
}
}
// 获取HashMap的容量
private static int getCapacity(HashMap map) {
try {
Field field = HashMap.class.getDeclaredField("table");
field.setAccessible(true);
Object[] table = (Object[]) field.get(map);
return table == null ? 0 : table.length;
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
return -1;
}
}
}
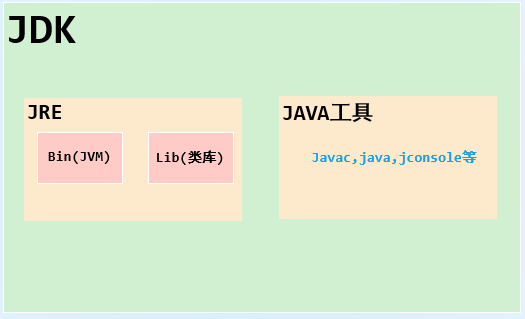
JDK,JRE,JVM
jdk = java development kit = java 开发工具 jre = java runtime enviroment = java 运行时环境 jvm = java virtual machine = java 虚拟机
jdk 目录下的 jre 目录下有 bin 即 jvm,目录 lib 是相关类库,所以三者关系如下图
java 源码通过 javac 编译为 .class 文件,该文件运行 windows版本 jvm 上则调用 windows 底层,运行在 linux jvm 上则调用 linux 底层依赖,所以是 class 文件通过不同操作系统的 jvm 实现跨平台。