01. shardingsphere
大约 5 分钟编程语言数据库mysql中间件
概述
使用 ShardingSphere 对MYSQL进行分库分表试验,创建的是 Springboot 项目,数据库位于本地的 lagou1 和 云服务器的 lagou2 ,其中的表结构都一样,没有使用 mybatis 转而使用了 jpa。要说明的是创建数据库时指定了主键是自增的但是在 springboot 项目中插入数据时也是可以手动指定主键的,并不会报错,注意要将 mode 的主键字段的注解 @GeneratedValue(strategy = GenerationType.IDENTITY) 注释掉。 本文是跟随拉勾的MYSQL视频试验分库分表的做法,使用了 ShardingSphere,测试用数据的建表语句如下
-- auto-generated definition
CREATE TABLE position (
Id BIGINT(11) AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(256) NULL,
salary VARCHAR(50) NULL,
city VARCHAR(256) NULL
)
CHARSET = utf8mb4;
-- auto-generated definition
CREATE TABLE position_detail (
id BIGINT(11) AUTO_INCREMENT PRIMARY KEY,
pid BIGINT(11) DEFAULT 0 NOT NULL,
description TEXT NULL
)
CHARSET = utf8mb4;
-- b_order 建表脚本
-- auto-generated definition
CREATE TABLE b_order (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
is_del BIT DEFAULT b'0' NULL COMMENT '默认0表示有效,1表示被删除',
company_id INT DEFAULT 0 NULL COMMENT '公司ID',
position_id INT DEFAULT 0 NULL COMMENT '职位ID',
user_id INT DEFAULT 0 NULL COMMENT '用户ID',
publish_user_id INT DEFAULT 0 NULL COMMENT '职位发布者ID',
resume_type INT DEFAULT 0 NULL COMMENT '默认0表示简历类型是附件,1表示在线',
status VARCHAR(256) DEFAULT '' NULL COMMENT '投递状态',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP NULL,
operate_time DATETIME DEFAULT CURRENT_TIMESTAMP NULL COMMENT '操作时间',
work_year VARCHAR(100) DEFAULT '' NULL COMMENT '工作年限',
name VARCHAR(256) DEFAULT '' NULL COMMENT '投递简历人名字',
position_name VARCHAR(256) DEFAULT '' NULL COMMENT '职位名称',
resumeId INT DEFAULT 0 NULL COMMENT '投递的简历ID'
) COMMENT '分库分表试验';
-- auto-generated definition
CREATE TABLE c_order (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id INT DEFAULT 0 NULL COMMENT '用户ID',
is_del BIT DEFAULT b'0' NULL,
company_id INT DEFAULT 0 NULL COMMENT '公司ID',
publish_user_id INT DEFAULT 0 NULL COMMENT 'B端用户ID',
position_id INT DEFAULT 0 NULL COMMENT '职位ID',
resume_type INT DEFAULT 0 NULL COMMENT '简历类型0表示附件,1为在线',
status VARCHAR(256) DEFAULT '' NULL,
create_time DATETIME DEFAULT CURRENT_TIMESTAMP NULL,
update_time DATETIME DEFAULT CURRENT_TIMESTAMP NULL
);
JPA最简示例
依赖版本号
Springboot 版本号
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.5.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
JPA依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
JPA模型类使用到的注解
下面是一个简单的模型类的案例,可以看到最简使用的注解
package com.xdf.sharding.model;
import javax.persistence.*;
import java.io.Serializable;
@Entity
@Table(name="position")
public class Position implements Serializable {
@Id
@Column(name="id")
// 表示自增主键,后面在手动添加数据的时候就不能设置主键值了
// 这里要注释掉以后添加数据时手动指定主键,那么以后就可以使用UUID
// 或者雪花片的方式指定主键达到分布式的效果
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
@Column(name="name")
private String name;
@Column(name="salary")
private String salary;
@Column(name="city")
private String city;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSalary() {
return salary;
}
public void setSalary(String salary) {
this.salary = salary;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
@Override
public String toString() {
return "Position{" +
"id=" + id +
", name='" + name + '\'' +
", salary='" + salary + '\'' +
", city='" + city + '\'' +
'}';
}
}
制作 DAO - Repository
package com.xdf.sharding.dao;
import com.xdf.sharding.model.Position;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.math.BigInteger;
public interface PositionRepository extends JpaRepository<Position,Long> {
@Query(nativeQuery = true,value="select p.id,p.name,pd.description from position p left join position_detail pd on p.id=pd.pid where p.id=:id")
public Object findPositionByid(@Param("id") long id);
}
上面案例中制作了自定义查询的方法,此时已经有增删改查等基本操作功能,使用 positionRepository.save(instance) 保存数据到表中,上面声明接口时泛型中指定的 Position 对应模型类的名称,后面的 Long 是标主键的数据类型
测试手动设置自增主键
- 将 model 下的 Position 的主键字段 id 上的注解 [@GeneratedValue(strategy ](/GeneratedValue(strategy ) = GenerationType.IDENTITY) 注释掉,该注解是使用雪花片分布式主键(或者UUID方式)时 ShardingSphere 使用的
- 可以通过 for 循环的方式手动填写实体对象的主键
测试雪花片分布式主键
- 将 model 包下的Position 的主键字段 id 上的注解 [@GeneratedValue(strategy ](/GeneratedValue(strategy ) = GenerationType.IDENTITY) 启用
- 设置配置文件 application-sharding-database.properties 中添加两行配置
# 使用雪花片的方式由 shrdingsphere 自动生成主键
spring.shardingsphere.sharding.tables.position.key-generator.column=id
spring.shardingsphere.sharding.tables.position.key-generator.type=SNOWFLAKE
- 第一行表示表 position 的字段 id 是主键,第二行表示使用雪花片类型的分布式主键,因为数据库中设置了字段 id 是整数类型所以这里使用了雪花片方式
制作自定义主键生成器
- 制作包 id
- 制作类 MyDistId,并且实现接口 ShardingKeyGenerator
- 在 resources 下制作目录 META-INF/services ,注意这里是两层目录
- 在上面创建的目录 services 下创建名称为 org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator 的文件,在其中写入实现自定义主键的类的全限定名(即包名+类名称) com.xdf.sharding.id.MyDistId
- 然后修改配置文件 application-sharding-database.properties 中的雪花片行为
# 下面的 ccDistKey 是自定义的分布式主键的类型名称
# 原本使用的是 SNOWFLAKE
spring.shardingsphere.sharding.tables.position.key-generator.type=ccDistKey
主从分库
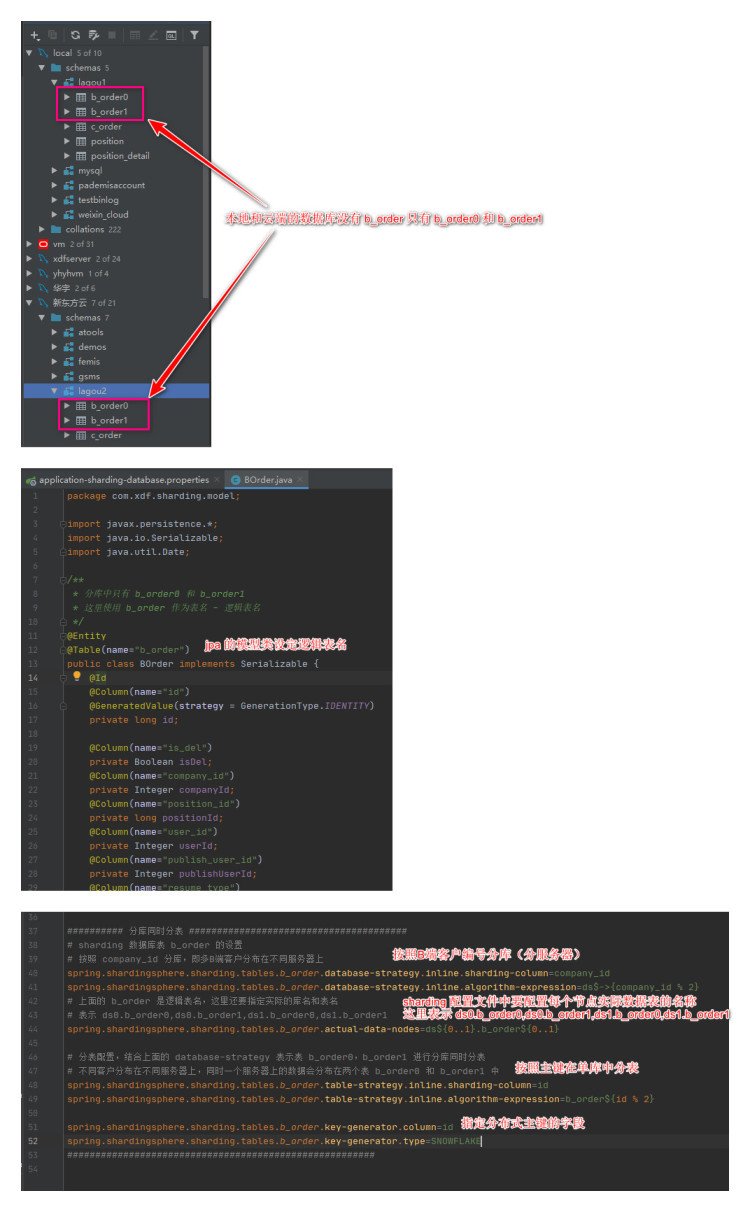
关于 shardingsphere 的配置文件 D:\software\ideaProjs\sharding\src\main\resources\application-sharding-database.properties 中关于主从一起分库的配置如下图 
分库的同时分表
本案例是拿表 b_order 首先分库到 ds0 和 ds1 两个数据库(即两个服务器),按照B端客户的编号平均分配到两个服务器上,同时每个服务器上又做分表,将 b_order 的数据分配到 b_order1 和 b_order2 中,相关的配置文件如下图